


iBatis开发详解(9)---查询复杂集合
通常我们使用iBatis的select查询都是映射的简单对象,即便在一个查询中连接多个表也是如此,那么既然iBatis是SQL Mapper,也就是说它可以映射复杂集合,我们来看看如何让对象模型向数据模型(关系型数据模型)靠拢。
我们的数据库设计如下:
CREATE TABLE `user` (
`userId` int(11) NOT NULL AUTO_INCREMENT ,
`userName` varchar(50) NULL DEFAULT NULL ,
`password` varchar(32) NULL DEFAULT NULL ,
`mobile` varchar(11) NULL DEFAULT NULL ,
`email` varchar(50) NULL DEFAULT NULL ,
`age` int(3) NULL DEFAULT NULL ,
PRIMARY KEY (`userId`)
)
CREATE TABLE `order` (
`orderId` int(11) NOT NULL AUTO_INCREMENT ,
`orderName` varchar(50) NULL DEFAULT NULL ,
`generateTime` datetime NULL DEFAULT NULL ,
`userId` int(11) NULL DEFAULT NULL ,
PRIMARY KEY (`orderId`)
)
CREATE TABLE `orderItem` (
`orderItemId` int(11) NOT NULL AUTO_INCREMENT ,
`itemName` varchar(50) NULL DEFAULT NULL ,
`quantity` int(3) NULL DEFAULT NULL ,
`price` float NULL DEFAULT NULL ,
`orderId` int(11) NOT NULL ,
PRIMARY KEY (`orderItemId`)
)
下面我们设计POJO来描述这三个对象:
package ibatis.model;
public class OrderItem implements java.io.Serializable {
private Integer orderItemId;
private String itemName;
private int quantity;
private float price;
private Integer orderId;
public OrderItem() {
}
public OrderItem(Integer orderItemId, String itemName, int quantity,
float price, Integer orderId) {
super();
this.orderItemId = orderItemId;
this.itemName = itemName;
this.quantity = quantity;
this.price = price;
this.orderId = orderId;
}
//Setters And Getters
public String toString() {
return "OrderItem [itemName=" + itemName + ", orderItemId=" + orderItemId+ ", orderId=" + orderId + ", price=" + price + ", quantity="
+ quantity + "]";
}
}
package ibatis.model;
import java.util.Arrays;
public class OrderInfo {
private Order order;
private OrderItem[] orderItemList;
public Order getOrder() {
return order;
}
public void setOrder(Order order) {
this.order = order;
}
public OrderItem[] getOrderItemList() {
return orderItemList;
}
public void setOrderItemList(OrderItem[] orderItemList) {
this.orderItemList = orderItemList;
}
public String toString() {
return "OrderInfo [order=" + order + ", orderItemList="
+ Arrays.toString(orderItemList) + "]";
}
}
package ibatis.model;
import java.util.Arrays;
public class UserInfo {
private User user;
private OrderInfo[] orderList;
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
public OrderInfo[] getOrderList() {
return orderList;
}
public void setOrderList(OrderInfo[] orderList) {
this.orderList = orderList;
}
public String toString() {
return "UserInfo [orderList=" + Arrays.toString(orderList) + ", user="+ user + "]";
}
} 那么实体对象和数据表我们就都有了,下面来编写iBatis的sqlMap文件来描述它们之间的关系,我们自定义resultMap来说明:
<resultMap class="ibatis.model.OrderItem" id="ResultOrderItemMap">
<result property="orderId" column="orderId" />
<result property="orderItemId" column="orderItemId" />
<result property="itemName" column="itemName" />
<result property="quantity" column="quantity" />
<result property="price" column="price" />
</resultMap>
<resultMap class="ibatis.model.OrderInfo" id="ResultOrderInfoMap">
<result property="order.orderId" column="orderId" />
<result property="order.orderName" column="orderName" />
<result property="order.generateTime" column="generateTime" />
<result property="orderItemList" select="pioneer.getOrderItemList"
column="orderId" />
</resultMap>
<select id="getOrderItemList" resultMap="ResultOrderItemMap">
select
orderId,
orderItemId,
itemName,
quantity,
price
from
orderItem
where
orderId = #orderId#
</select>
<resultMap class="ibatis.model.UserInfo" id="ResultUserInfoMap">
<result property="user.userId" column="userId" />
<result property="user.userName" column="userName"/>
<result property="orderList" select="pioneer.getOrderInfoList"
column="userId" />
</resultMap>
<select id="getOrderInfoList" resultMap="ResultOrderInfoMap">
select
orderId,
orderName,
generateTime
from
test.order
where
userId = #userId#
</select>
<select id="getUserInfoList" resultMap="ResultUserInfoMap">
select
userId,
userName
from
user
</select>
那么示例程序就很简单了:
package ibatis;
import ibatis.model.UserInfo;
import java.io.IOException;
import java.io.Reader;
import java.util.ArrayList;
import com.ibatis.common.resources.Resources;
import com.ibatis.sqlmap.client.SqlMapClient;
import com.ibatis.sqlmap.client.SqlMapClientBuilder;
public class UserInfoDemo {
private static String config = "ibatis/SqlMapConfig.xml";
private static Reader reader;
private static SqlMapClient sqlMap;
static {
try {
reader = Resources.getResourceAsReader(config);
} catch (IOException e) {
e.printStackTrace();
}
sqlMap = SqlMapClientBuilder.buildSqlMapClient(reader);
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
ArrayList<UserInfo> userInfoList = (ArrayList<UserInfo>) sqlMap
.queryForList("pioneer.getUserInfoList");
long end = System.currentTimeMillis();
System.out.println(userInfoList);
System.out.println((end - start) + " ms");
}}
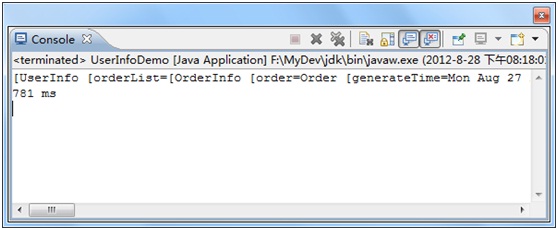
查询得到的内容为:
[UserInfo [orderList=[OrderInfo [order=Order [generateTime=Mon Aug 27 21:35:27 CST 2012, orderId=1, orderItems=null, orderName=Mobile Phone], orderItemList=[OrderItem [itemName=Moto MB525, orderItemId=1, orderId=1, price=1000.0, quantity=1], OrderItem [itemName=Moto MB526, orderItemId=2, orderId=1, price=1200.0, quantity=1]]], OrderInfo [order=Order [generateTime=Mon Aug 27 22:28:38 CST 2012, orderId=2, orderItems=null, orderName=Laptop], orderItemList=[OrderItem [itemName=Lenovo X201, orderItemId=3, orderId=2, price=5000.0, quantity=1], OrderItem [itemName=Lenovo X220, orderItemId=4, orderId=2, price=7000.0, quantity=1]]]], user=User [age=0, email=null, mobile=null, password=null, userId=1, userName=Sarin]]]
他们都是以对象的形式来描述的,因为我们命没有查询user的email,mobile等信息,所以它们是null。
程序编写完了,但是问题随之而来。先看这么一大堆的输出,我们仅仅有1个用户的两个订单,每个订单仅包含2个项。如果我们的系统内有10000个用户,每个用户下了100个订单,每个订单有5项,那么一次查询结果就会生成500万个对象,显然在数据不是很多时,就已经带来了问题。首先这是一个数据库I/O的问题,大量数据库I/O和内存对象,降低了性能,消耗了资源。其次是N+1查询问题。
N+1问题也好理解,在本例中,我们要查询一个用户的N个订单,还要查询这N个订单中每个订单的N个订单项,就产生了N+1查询问题。
iBatis提供了针对每个问题的解决方案,但是却不能同时解决这两个问题。
针对数据库I/O,我们很容易想到延迟加载的特性,就是对于所有数据并不是一次全部查出,在需要的时候继续进行查询,那么就会大幅度减少数据库的I/O,开启iBatis的延迟加载特性非常简单,只需修改如下XML设置即可:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE sqlMapConfig
PUBLIC "-//ibatis.apache.org//DTD SQL Map Config 2.0//EN"
"http://ibatis.apache.org/dtd/sql-map-config-2.dtd">
<sqlMapConfig>
......
<settings useStatementNamespaces="true" lazyLoadingEnabled="true" />
......
</sqlMapConfig>
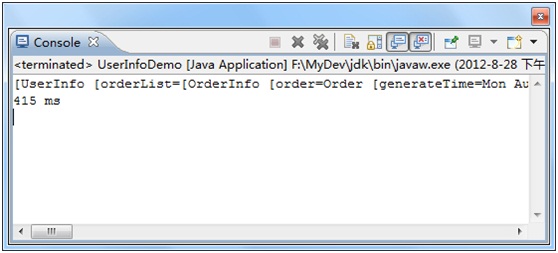
可以看到,在仅有的几条数据时,所消耗的时间也大幅减少,说明延迟加载特性已经启用。
下面我们来看针对N+1查询问题的解决方案,那就是使用iBatis在resultMap中为我们提供的groupBy属性。我们将上面的XML文件修改如下:
<resultMap class="ibatis.model.UserInfo" id="ResultUserInfoMapN" groupBy="user.userId">
<result property="user.userId" column="userId" />
<result property="user.userName" column="userName"/>
<result property="orderList" resultMap="pioneer.ResultOrderInfoMapN" />
</resultMap>
<resultMap class="ibatis.model.OrderInfo" id="ResultOrderInfoMapN" groupBy="order.orderId">
<result property="order.orderId" column="orderId" />
<result property="order.orderName" column="orderName" />
<result property="order.generateTime" column="generateTime" />
<result property="orderItemList" resultMap="pioneer.ResultOrderItemMapN" />
</resultMap>
<resultMap class="ibatis.model.OrderItem" id="ResultOrderItemMapN">
<result property="orderId" column="orderId" />
<result property="orderItemId" column="orderItemId" />
<result property="itemName" column="itemName" />
<result property="quantity" column="quantity" />
<result property="price" column="price" />
</resultMap>
<select id="getUserInfoListN" resultMap="ResultUserInfoMapN">
select
user.userId as userId,
user.userName as userName,
test.order.orderId as orderId,
test.order.orderName as orderName,
test.order.generateTime as generateTime,
orderItem.*
from
user join test.order on user.userId=test.order.userId join orderItem on test.order.orderId=orderItem.orderId
order by
userId,test.order.orderId,orderItemId
</select>
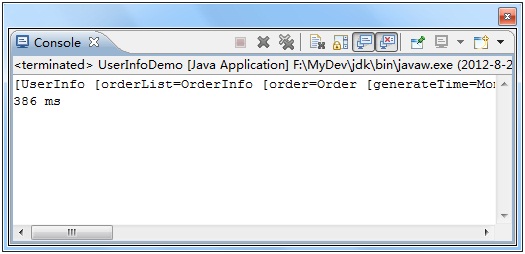
也可以看到查询效率的显著提升。
综上所述,延迟加载适用于大型数据集合,但是并非其中的每条记录都会被用到。此方法前期的性能大幅度提高,但是后期仍需加载所需数据。而N+1查询解决方案适用于小型数据集合或者是所有数据都肯定会被用到的数据集合,使得整体性能得到提高。


更多建议: