


iBatis开发详解(7)---执行非查询语句(CRUD,函数和过程
CRUD操作中除了查询操作,其他都统一称为更新操作,因为增删改都是更新数据库表的,SqlMap API中对应的方法就是insert,update和delete,我们逐一来看。
insert方法的方法签名为:Object insert(String id, String parameterObject) throws SQLException。那么我们需要传递的参数就是XML文件中的映射语句名称和执行插入操作所需要的参数。返回值为Object类型,也就是说它可以返回一个对象。我们想想通过插入语句我们希望得到什么呢?没错,就是插入这条记录的主键。
这里还不得不多说一下主键的问题。虽然每种数据库都有自己主键的生成方式,但对于这种将数据插入到数据库后立即要知道主键的情况,就会产生问题。iBatis中的insert元素的一个子元素selectKey可以帮助我们获取自动生成的主键并保存在返回对象中,它有两种调用方式:
第一就是数据插入到数据库中之后立即抓取这条记录的主键的值,但此时要注意抓取的值确实是刚插入的记录的,也就是说数据库的驱动支持这么操作。如果有两个线程同时执行insert操作,其可能的顺序为insert #1,insert #2,selectKey #1,selectKey #2,那么在执行selectKey #1时得到的就是第二个记录的主键值了,这显然对程序产生了影响。
第二种方式就是在插入记录之前就获取键,然后连同这个键一同插入到数据库中,这样就不存在第一种情况的风险,是安全的操作。这种方式更倾向于支持序列的数据库。
在MySQL数据库中没有序列的支持,那么可以使用LAST_INSERT_ID()函数来获取自动生成的主键,我们来一段代码:
<insert id="addUser" parameterClass="parameterMap" >
insert into users(USERNAME,PASSWORD,AGE,MOBILE,EMAIL)
values(#userName:VARCHAR#,#password:VARCHAR#,#age:INT#,#mobile:VARCHAR#,#email:VARCHAR#)
<selectKey keyProperty="userId" resultClass="int">
select LAST_INSERT_ID()
</selectKey>
</insert>
ParameterMap parameterMap = new ParameterMap("userName", "sarin",
"password", "123", "age", "23", "mobile", "1", "email", "@");
Object obj = sqlMap.insert("User.addUser", parameterMap);
System.out.println(obj);
上面我们在执行更新操作时传递的参数是我们写好的ParameterMap类型,即:
package ibatis.util;
import java.util.HashMap;
public class ParameterMap extends HashMap<Object, Object> {
private static final long serialVersionUID = 1L;
public ParameterMap(Object... parameters) {
for (int i = 0; i < parameters.length - 1; i += 2) {
super.put(parameters[i], parameters[i + 1]);
}
}
}
User user = new User(null, "sarin", "123", "15940900000", "@", 23);
Object obj = sqlMap.insert("User.addUser", user);
System.out.println(obj);
<parameterMap class="ibatis.util.User" id="userPramaterMap">
<parameter property="userName" jdbcType="VARCHAR" />
<parameter property="password" jdbcType="VARCHAR" />
<parameter property="age" jdbcType="INT" />
<parameter property="mobile" jdbcType="VARCHAR" />
<parameter property="email" jdbcType="VARCHAR" />
</parameterMap>
<insert id="addUserUseParameterMap" parameterMap="userPramaterMap">
insert into
users(USERNAME,PASSWORD,AGE,MOBILE,EMAIL)
values(?,?,?,?,?)
<selectKey keyProperty="userId" resultClass="int">
select LAST_INSERT_ID()
</selectKey>
</insert>
User user = new User(null, "sarin", "123", "15940900000", "@", 23);
Object obj = sqlMap.insert("User.addUserUseParameterMap", user);
System.out.println(obj);
要注意的一点是iBatis允许在一条SQL语句中更新一条或多条记录,而其他面向对象的工具是只允许修改一条记录(比如Hibernate),但Hibernate针对批量操作也做了处理。
说到批量操作,就会有并发的问题,那么事务机制很自然就要想到了,这里简单介绍一下iBatis处理批量操作的方法,后面会有详细介绍iBatis的事务。这里给出一个处理并发的小技巧,就是在高并发的数据表中加一个时间戳字段或者是版本字段控制,每次更新操作都修改这个字段,就能一定程度上控制数据完整性。
由于iBatis是SQL映射工具,那么就不需要像使用Hibernate那样考虑对象间的关系,在程序中做好处理就行了。先看下面这个示例:购物车订单,这是很经典的示例,我们需要建立两个类(订单和订单项),两个SQL映射文件和一个测试类。数据库表结构如下:
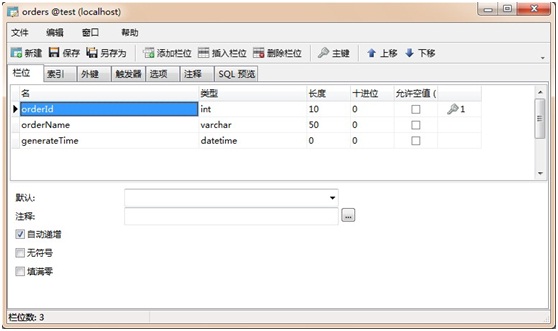
这是订单表,简单做示例,就订单名称和生成订单的时间两项即可。
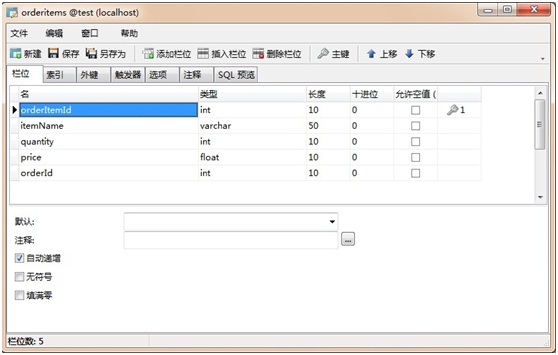
这是订单项表,字段见名知意,这里就不多解释了。下面来看看实体类的设计:
package ibatis.model;
import java.util.Date;
import java.util.List;
public class Order implements java.io.Serializable {
private Integer orderId;
private String orderName;
private java.util.Date generateTime;
private List<OrderItem> orderItems;
public Order() {
}
public Order(Integer orderId, String orderName, Date generateTime,
List<OrderItem> orderItems) {
super();
this.orderId = orderId;
this.orderName = orderName;
this.generateTime = generateTime;
this.orderItems = orderItems;
}
// 省略getter和setter方法
@Override
public String toString() {
return "Order [generateTime=" + generateTime + ", orderId=" + orderId+ ", orderItems=" + orderItems + ", orderName=" + orderName+ "]";
}
}
下面是订单项的实体类,也很简单:
package ibatis.model;
public class OrderItem implements java.io.Serializable {
private Integer oderItemId;
private String itemName;
private int quantity;
private float price;
private Integer orderId;
public OrderItem() {
}
public OrderItem(Integer oderItemId, String itemName, int quantity,
float price, Integer orderId) {
super();
this.oderItemId = oderItemId;
this.itemName = itemName;
this.quantity = quantity;
this.price = price;
this.orderId = orderId;
}
// 省略getter和setter方法
@Override
public String toString() {
return "OrderItem [itemName=" + itemName + ", oderItemId=" + oderItemId+ ", orderId=" + orderId + ", price=" + price + ", quantity="
+ quantity + "]";
}
}
<sqlMap namespace="Order">
<typeAlias alias="Order" type="ibatis.model.Order" />
<insert id="insert" parameterClass="Order">
insert into
orders(orderName,generateTime)
values
(#orderName:VARCHAR#,now())
<selectKey keyProperty="orderId" resultClass="int">
select LAST_INSERT_ID()
</selectKey>
</insert>
<update id="update" parameterClass="Order">
update
orders
set
<dynamic>
<isNotEmpty property="orderName">
orderName=#orderName:VARCHAR#
</isNotEmpty>
</dynamic>
where
orderId=#orderId:INT#
</update>
<delete id="deleteDetails" parameterClass="Order">
delete from
orderitems
where
orderId=#orderId:INT#
</delete>
</sqlMap>
<sqlMap namespace="OrderItem">
<typeAlias alias="OrderItem" type="ibatis.model.OrderItem" />
<insert id="insert" parameterClass="OrderItem">
insert into
orderitems(itemName,quantity,price,orderId)
values (#itemName:VARCHAR#,#quantity:INT#,#price:FLOAT#,#orderId:INT#)
</insert>
</sqlMap>
package ibatis;
// 省略包引入语句
public class OrderDemo {
private static String config = "ibatis/SqlMapConfig.xml";
private static Reader reader;
private static SqlMapClient sqlMap;
static {
try {
reader = Resources.getResourceAsReader(config);
} catch (IOException e) {
e.printStackTrace();
}
sqlMap = SqlMapClientBuilder.buildSqlMapClient(reader);
}
public static void main(String[] args) throws SQLException{
OrderItem item1 = new OrderItem(null, "IBM THINKPAD T410", 1, 10000, null);
OrderItem item2 = new OrderItem(null, "HP 6930P", 1, 7000, null);
OrderItem item3 = new OrderItem(null, "APPLE MC024", 1, 16000, null);
// 创建OrderItem对象集合,放入三个购物项
List<OrderItem> orderItems = new ArrayList<OrderItem>();
orderItems.add(item1);
orderItems.add(item2);
orderItems.add(item3);
Order order = new Order(null, "Sarin's Order", null, orderItems);
saveOrder(sqlMap, order);
}
public static void saveOrder(SqlMapClient sqlMap, Order order)
throws SQLException {
// 判断是插入订单还是更新
if (null == order.getOrderId()) {
sqlMap.insert("Order.insert", order);
} else {
sqlMap.update("Order.update", order);
}
// 清除订单原有信息
sqlMap.delete("Order.deleteDetails", order);
// 插入订单项目
for (int i = 0; i < order.getOrderItems().size(); i++) {
OrderItem oi = order.getOrderItems().get(i);
oi.setOrderId(order.getOrderId());
sqlMap.insert("OrderItem.insert", oi);
}
}
}
public static void main(String[] args) throws SQLException {
long start = System.currentTimeMillis();
// 中间执行代码
long end = System.currentTimeMillis();
System.out.println(end - start);
}
public static void main(String[] args) throws SQLException,IOException {
long start = System.currentTimeMillis();
String config = "ibatis/SqlMapConfig.xml";
Reader reader= Resources.getResourceAsReader(config);
SqlMapClient sqlMap = SqlMapClientBuilder.buildSqlMapClient(reader);
/ 中间执行代码
long end = System.currentTimeMillis();
System.out.println(end - start);
}
public static void saveOrder(SqlMapClient sqlMap, Order order)
throws SQLException {
// 开启事务
sqlMap.startTransaction();
try {
// 判断是插入订单还是更新
if (null == order.getOrderId()) {
sqlMap.insert("Order.insert", order);
} else {
sqlMap.update("Order.update", order);
}
// 开始批量操作
sqlMap.startBatch();
// 清除订单原有信息
sqlMap.delete("Order.deleteDetails", order);
// 插入订单项目
for (int i = 0; i < order.getOrderItems().size(); i++) {
OrderItem oi = order.getOrderItems().get(i);
oi.setOrderId(order.getOrderId());
sqlMap.insert("OrderItem.insert", oi);
}
sqlMap.executeBatch();
sqlMap.commitTransaction();
} finally {
sqlMap.endTransaction();
}
}
最后就是存储过程了,这里给出一个简单的示例:在存储过程中删除订单详细项,一个比较奇怪的地方就是iBatis调用mysql的存储过程要使用insert()方法,这里并不知道其原因。首先我们定义一个存储过程:
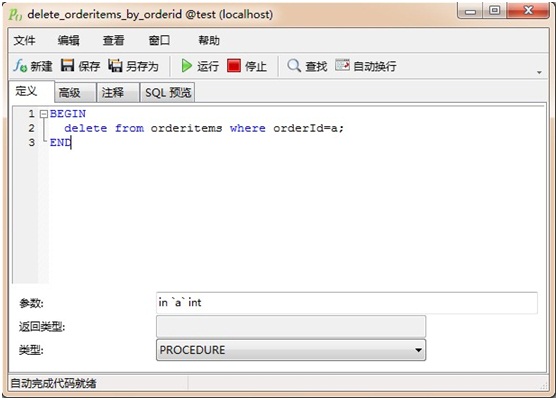
在SQL配置中,我们定义一个存储过程和映射参数类型:
<parameterMap class="java.util.Map" id="pm_delOiByOId">
<parameter property="orderId"/>
</parameterMap>
<procedure id="deleteOrderitemsByOrderId" parameterMap="pm_delOiByOId" resultClass="int">
call delete_orderitems_by_orderid(?)
</procedure>
Map m = new HashMap();
m.put("orderId", 3);
sqlMap.queryForObject("Order.deleteOrderitemsByOrderId", m);
CREATE DEFINER = `root`@`localhost` FUNCTION `max_in_example`(`a` int,`b` int)
RETURNS int(10)
BEGIN
if(a > b) then
return a;
else
return b;
end if;
END;
<parameterMap class="java.util.Map" id="pm_in_example">
<parameter property="a"/>
<parameter property="b"/>
</parameterMap>
<select id="in_example" parameterMap="pm_in_example" resultClass="int">
select max_in_example(?,?)
</select>
Map m = new HashMap(2);
m.put("a", new Integer(7));
m.put("b", new Integer(5));
Integer val = (Integer) sqlMap.queryForObject("User.in_example", m);
System.out.println(val);


更多建议: