


软件工程 分析和设计工具
软件分析和设计包括所有有助于将需求规格说明转换为实现的活动。需求规格说明指定了软件的所有功能和非功能的期望。这些需求规范以人类可读和可理解的文档形式出现,计算机与之无关。
软件分析和设计中间阶段,帮助将人类可读的需求转化为实际代码。
让我们来看看设计师使用的几个分析和设计工具:
数据流图
数据流图是在信息系统中数据流的图形表示。它是能够描述输入数据流,输出数据流和存储数据。DFD中没有提到有关数据如何流经系统的任何内容。
DFD 和流程图之间有着一个显著的差异。流程图描述了在流动的程序模块的控制流程。 DFD的描述了系统中各个级别的数据流。 DFD 不含有任何控制或分支元素。
DFD的类型
数据流图是逻辑或物理.
- 逻辑DFD: 这种类型的 DFD 专注于系统进程和系统中的流数据。例如,在银行软件系统中,数据是如何的不同实体之间移动。
- 物理DFD: 这种类型的 DFD 显示了数据流是如在系统中实际实现的。它是更具体,更接近于实现。
DFD组件
DFD 可以使用以下组件集表示数据的来源、目的地、存储和流:

- 实体:是信息数据的来源和地。实体是由各自名称的矩形表示。
- 过程:对数据采取的活动和操作由圆形或圆边矩形表示。
- 数据存储:数据存储有两种变体,它可以表示没有两个较小边的矩形,或者表示为仅缺少一侧的开发边矩形。
- 数据流:数据的移动用尖箭头表示。数据移动显示为从箭头底部作为其源向箭头头部作为目的地。
DFD水平
- 0级 - 最高抽象层次的 DFD 被称为 0 级 DFD,它将整个信息系统描述为一个隐藏所有底层细节的图表。级别 0 DFD 也被称为上下文级别 DFD。
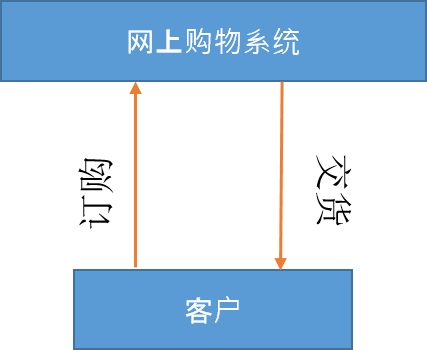
- 1级 - 0 级 DFD 被细分成更具体的 1 级 DFD。级别 1 DFD 描述了系统中的基本模块以及各个模块之间的数据流。1 级 DFD 还提到了基本流程和信息来源。
- 2级 - 在这个级别,DFD 显示了数据级别 1 中所提到的模块内的流动方式。
除非达到所需的规范级别,否则更高级别的 DFD 可以转换为更具体的更低级别的 DFD,具有更深层次的理解。
结构图
结构图是衍生自数据流图的图表。它比 DFD 更详细地表示系统。它将整个系统分解为最低的功能模块,比 DFD 更详细地描述系统每个模块的功能和子功能。
结构图表示模块的层次结构。在每一层执行某一特定任务.
以下是在建结构图中使用的符号:
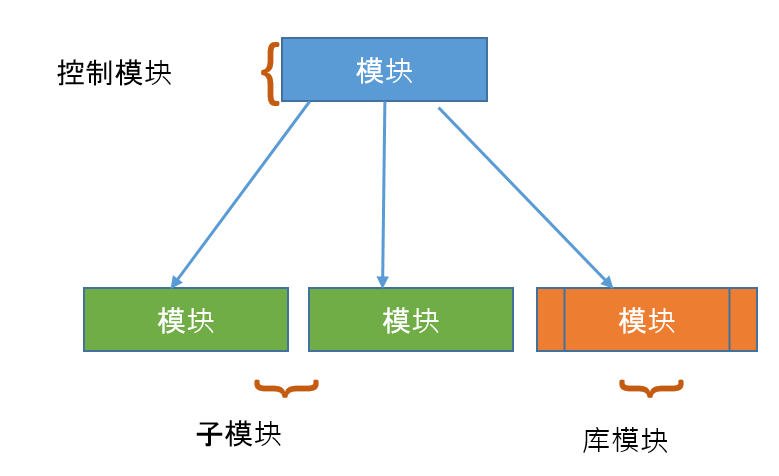
- 模块 - 它代表进程或子程序或任务。一个控制模块分支到一个以上的子模块。库模块可重复使用并可从任何模块调用。
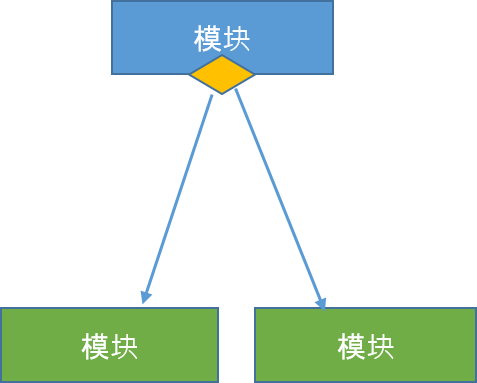
- 状态 - 它由模块底部的小菱形表示。它描述了控制模块可以根据某些条件选择任意的子程序。
- 跳转 - 显示的箭头指向模块内部,表示控件将在子模块的中间跳转。

- 循环 - 弯曲的箭头表示模块中的循环。循环重复执行模块覆盖的所有子模块。
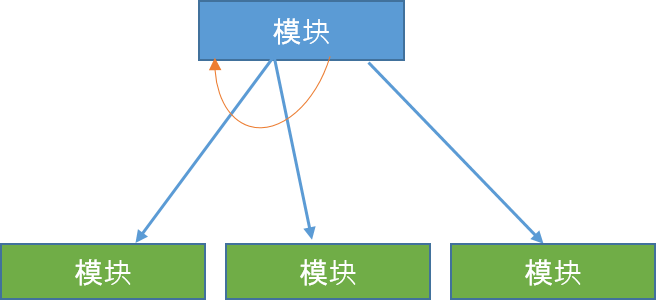
- 数据流 - 末端带有空心圆圈的有向箭头表示数据流。

- 控制流 - 末端带有实心圆圈的有向箭头表示控制流。
HIPO图
HIPO(HIerarchical Input Process Output,分层输入过程输出)图是结合两种有组织的方法来分析系统并提供文档的手段。HIPO 模型由 IBM 于 1970 年开发。
HIPO 图表示软件系统模块的层次结构。分析师使用 HIPO 图,以获得对系统功能的高级视图。它以分层方式将功能分解为子功能。它描述了系统执行的功能。
HIPO 图适用于文档目的。它们的图形表示使设计人员和管理人员更容易获得系统结构的图形概念。
与描述模块中控制和数据流的 IPO(Input Process Output,输入过程输出)图相比,HIPO 不提供任何有关数据流或控制流的信息。

示例
HIPO图、层级表示的 IPO 图这两个部分都用于软件程序的结构设计及其文档。
结构化英语
大多数程序员不了解软件的大局,所以他们只依赖于他们的经理告诉他们做什么。为程序员提供准确的信息以开发准确而快速的代码是高级软件管理人员的责任。
因此,该软件的分析师和设计师提出了诸如结构化英语之类的工具。它只不过是对编码所需的内容以及如何编码的描述。结构化英语帮助程序员编写无错误的代码。
使用图形或图表的其他形式的方法有时可能会被不同的人以不同的方法理解。在这里,结构化英语和伪代码试图缩小这种理解差距。
结构化英语是它在结构化编程范式中使用简单的英语单词。但这不是最终的代码,而是一种描述需要编码什么以及如何编码。以下是结构化编程的一些标记。
IF-THEN-ELSE,DO-WHILE-UNTIL
分析师使用相同的变量和数据的名称,它存储在数据字典,这使得编写和理解代码变的更加简单。
例如
我们以在线购物环境中的客户身份验证为例。此验证客户的程序可以用结构化英语编写为:
Enter Customer_NameSEEK Customer_Name in Customer_Name_DB fileIF Customer_Name found THEN Call procedure USER_PASSWORD_AUTHENTICATE()ELSE PRINT error message Call procedure NEW_CUSTOMER_REQUEST()ENDIF
用结构化英语编写的代码更像是日常口语。它不能直接作为软件代码来实现。结构化英语独立于编程语言。
伪代码
伪代码的编写更接近于编程语言。它可以被认为是增强的编程语言,充满了注释和描述。
伪代码避免了变量声明,但它们使用一些实际的编程语言结构编写的,如 C,Fortran 和 Pascal 等。
伪代码包含比结构化英语更多的编程细节。它提供了一种执行任务的方法,就好像计算机正在执行代码一样。
示例
打印最多 n 个数字的斐波那契数列的程序。
void function FibonacciGet value of n;Set value of a to 1;Set value of b to 1;Initialize I to 0for (i=0; i< n; i++){ if a greater than b { Increase b by a; Print b; } else if b greater than a { increase a by b; print a; }}
决策表
决策表以结构化的表格格式表示条件以及为解决这些条件而要采取的相应措施。
它是调试和防止错误的强大工具。它有助于将相似的信息分组到一个表中,然后通过组合表来提供简单方便的决策。
建立决策表
要建立决策表,开发人员必须遵循四个基本步骤:
- 确定要解决的所有可能条件
- 确定针对所有已识别条件的操作
- 创建最大可能规则
- 为每个规则定义操作
示例
让我们举一个简单的例子来说明我们的互联网连接的日常问题。我们首先确定启动互联网时可能出现的所有问题及其各自可能的解决方案。
我们列出了列条件下所有可能的问题以及列操作下的预期操作。
| - | Conditions/Actions | Rules | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Conditions | Shows Connected | N | N | N | N | Y | Y | Y | Y |
| - | Ping is Working | N | N | Y | Y | N | N | Y | Y |
| - | Opens Website | Y | N | Y | N | Y | N | Y | N |
| Actions | Check network cable | X | |||||||
| - | heck internet router | X | X | X | X | ||||
| - | tart Web Browser | X | |||||||
| - | ontact Service provider | X | X | X | X | X | X | ||
| - | Do no action |
表 : 决策表 – 在内部网络故障排除
实体 - 关系模型
实体关系模型是一种基于现实世界实体和它们之间的关系概念的数据库模型。我们可以将现实世界的场景映射到 ER 数据库模型上。ER 模型创建一组实体及其属性、一组约束和它们之间的关系。
ER 模型最适用于数据库的概念设计。 ER 模型可以如下表示:

- 实体:ER 模型中的实体是真实世界的存在,它具有一些称为属性的属性。每个属性都由其相应的值集定义,称为域。
例如, 考虑一个学校的数据库。在这里,学生是一个实体。学生也有各种属性,如姓名、身份证、年龄和班级等。 - 关系:实体之间的逻辑关联被称为关系。关系以各种方式与实体映射。映射基数定义了两个实体之间的关联数。
映射基数:- 一对一
- 一对多
- 多对一
- 多对多
数据字典
数据字典是关于数据信息的集中收集。它存储数据的含义和来源、它与其他数据的关系、使用的数据格式等。数据字典对所有名称都有严格的定义,以方便用户和软件设计人员。
数据字典通常被称为元数据(关于数据的数据)存储库。它是与软件程序的 DFD(数据流图)模型一起创建的,并且预计会在 DFD 更改或更新时进行更新。
数据字典的要求
在设计和实现软件时通过数据字典引用数据。数据字典消除了任何歧义的可能性。它有助于保持程序员和设计人员的工作同步,同时在程序中的任何地方使用相同的对象引用。
数据字典为整个数据库系统提供了一种在一个地方记录的方式。DFD 的验证是使用数据字典进行的。
内容
数据字典中应包含以下内容的信息
- 数据流
- 数据结构
- 数据元素
- 数据存储
- 数据处理
数据流是通过前面研究过的 DFD 来描述的,并以所描述的代数形式表示。
| = | Composed of |
|---|---|
| {} | Repetition |
| () | Optional |
| + | And |
| [ / ] | Or |
示例
Address = House No + (Street / Area) + City + StateCourse ID = Course Number + Course Name + Course Level + Course Grades
数据元素
数据元素由数据和控制项的名称和描述、内部或外部数据存储等组成,具有以下详细信息:
- 主要名称
- 次要名称 (别名)
- 用例(如何以及在何处使用)
- 内容描述(符号等)
- 补充信息(预设值,约束等)
数据存储
它存储数据从何处进入系统和存在于系统外的信息。数据存储可能包括:
- 文件
- 软件内部。
- 软件外部,但在同一台机器上。
- 位于不同机器上的软件和系统外部。
- 表
- 命名约定
- 索引属性
数据处理
有两种类型的数据处理:
- 逻辑: 正如用户所见。
- 物理: 正如软件所见。


更多建议: