


Samza 主机关联和 YARN
在 Samza 中,容器是在一组机器上运行的物理并行单元。每个容器本质上是一个运行一个或多个流任务的进程。每个任务实例消耗输入流的一个或多个分区,并与其自己的持久数据存储相关联。
我们将一个状态 Samza 作业定义为在其实现中使用键值存储的 Samza 作业以及关联的 changelog 流。在有状态的 samza 作业中,可以将任务配置为使用多个存储。对于每个存储,在任务实例和数据存储之间存在1:1映射。由于向 Yarn 群集中的机器分配容器完全由 Yarn 分配,所以 Samza 不保证将容器(因此与其关联的任务)部署在同一台机器上。容器可以在以下任何情况下进行洗牌:
- 当通过指向 yarn.package.path 新的包路径升级作业并重新提交。
- 当工作只是由 Yarn 或用户重新启动时。
- 容器故障或提前引发 SamzaAppMaster 重新分配到另一个可用资源时。
在任何上述情况下,任务的共用数据需要在每次容器启动时恢复。每次恢复数据可能是昂贵的,特别是对于具有大数据集的应用程序。这种行为会使工作的启动时间减慢,使得该作业不再“接近实时”。此外,如果多个有状态的 samza 作业在群集中同时重启,并且共享相同的 changelog 系统,则可以快速地使更改日志系统的网络饱和并导致 DDoS。
例如,考虑执行流表连接的 Samza 作业。通常,这样的工作要求数据集在开始处理输入流之前在所有处理器上可用。数据集通常是大型(order> 1TB)只读数据,将用于连接或添加属性到传入的消息。该作业可以通过直接从远程存储或更改日志流的数据填充来初始化该缓存。每次重新启动容器时,都会发生此缓存初始化。这在工作启动期间会导致严重的延迟。
那么解决方案就是简单地将状态存储器保存在容器进程正在执行的机器上,并在每次重新启动作业时为容器重新分配相同的主机,以便重新使用持久化状态。因此,Samza 在作业重新启动时将容器分配到同一台机器的能力称为主机密切关系。Samza 利用主机关联来增强我们对当地国家重用的支持。
它是如何工作的?
当 Yarn 中部署有状态的 Samza 作业时,任务的状态存储位于 Yarn 应用尝试的当前工作目录中。
container_working_dir=${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/application_${appid}/container_${contid}/
# Data Stores
ls ${container_working_dir}/state/${store-name}/${task_name}/这允许节点管理器(NM)DeletionService 在应用程序完成或失败后清理工作目录。为了重新使用本地状态存储,状态存储需要保持在 NM 的删除服务范围之外。集群管理员应将此位置设置为纱线中的环境变量 LOGGED_STORE_BASE_DIR。
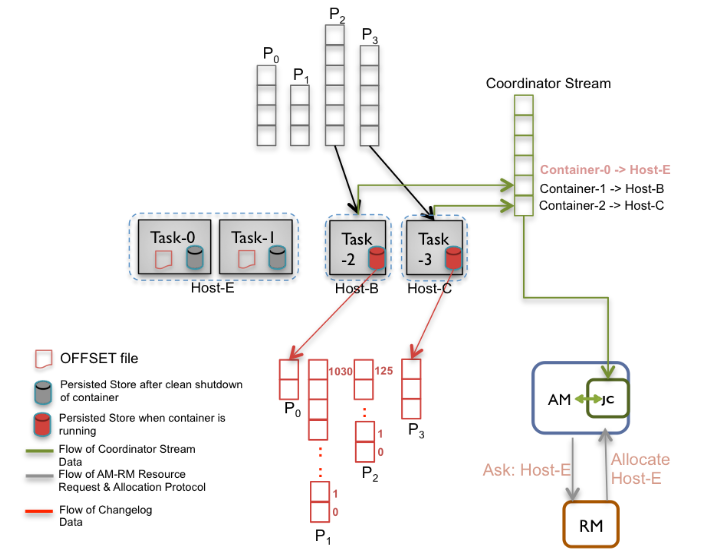
每次任务提交时,Samza 将最后一个实例化的偏移量从更改日志流中写入磁盘上的检查文件。这也是在容器关闭时完成的。因此,存在与每个状态存储的 changelog 分区相关联的 OFFSET文件,其由容器中的任务消耗。
${LOGGED_STORE_BASE_DIR}/${job.name}-${job.id}/${store.name}/${task.name}/OFFSET现在,在 OFFSET 文件存在之后,当容器在同一台机器上重新启动时,Samza 容器:
- 打开磁盘上的持久存储
- 读取 OFFSET 文件
- 从 OFFSET 值恢复状态存储
这大大降低了容器启动时的状态恢复时间,因为我们不再从日志流的开始消耗。如果 OFFSET 文件不存在,它将创建状态存储并从更改日志中的最旧偏移量中消耗以重新创建状态。由于 OFFSET 文件在刷新存储之后每次提交时都会写入,因此记录的偏移量将保证与存储的当前内容或某些较旧的内容对应,但不会更新。这给予状态恢复至少一次语义。因此,日志条目必须是幂等的。
有必要定期清理计算机上的未使用或孤立状态存储,以管理磁盘空间。此功能正在SAMZA-656中进行。
为了重新使用本地状态,Samza 必须从资源管理器(RM)成功地声明特定的主机。为了支持这一点,Samza 容器在每次启动成功时将其地点信息写入协调器流。现在,Samza应用程序主(AM)可以通过作业协调器(JC)识别最后一个已知的容器主机,并且应用程序不再与容器位置无关。在容器故障(由于上述引用的任何原因)中,AM包括ResourceRequest中预期资源的主机名。
请注意,Yarn 群集必须配置为使用公平调度程序,并启用连续调度。通过连续调度,调度程序不断地遍历集群中的所有节点,而不是依赖于节点的心跳,并且在放宽局部性之前,根据每个节点的先前已知状态来调度工作。因此,在配置的延迟之后,调度器处理轻松的位置。这种方法可以被认为是“ 尽力而为的粘性 ”策略,因为所请求的节点可能没有运行或在请求时没有足够的资源(即使数据存储中的状态可能被持续)。有关选择Fair Scheduler的更多详细信息,请参阅设计文档。
配置YARN群集以支持主机关联性
- 通过设置 LOGGED_STORE_BASE_DIR 在 yarn-env.sh 中的环境变量来启用本地状态重新使用 export LOGGEDSTOREBASE_DIR=<path-for-state-stores> 。如果没有这种配置,状态存储不会在容器关闭时持久存在。这将有效地意味着您不会重新使用本地状态,因此主机关联成为一个模拟操作。
- 使用公平调度器配置 Yarn,并在 yarn-site.xml 中启用连续调度
<property> <name>yarn.resourcemanager.scheduler.class</name> <description>The class to use as the resource scheduler.</description> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> </property> <property> <name>yarn.scheduler.fair.continuous-scheduling-enabled</name> <description>Enable Continuous Scheduling of Resource Requests</description> <value>true</value> </property> <property> <name>yarn.scheduler.fair.locality-delay-node-ms</name> <description>Delay time in milliseconds before relaxing locality at node-level</description> <value>1000</value> <!-- Should be tuned per requirement --> </property> <property> <name>yarn.scheduler.fair.locality-delay-rack-ms</name> <description>Delay time in milliseconds before relaxing locality at rack-level</description> <value>1000</value> <!-- Should be tuned per requirement --> </property> - 将纱线节点管理器SIGTERM配置为SIGKILL超时为合理时间节点管理器将给予Samza Container足够的时间在纱线站点.xml中执行干净的关机
<property> <name>yarn.nodemanager.sleep-delay-before-sigkill.ms</name> <description>No. of ms to wait between sending a SIGTERM and SIGKILL to a container</description> <value>600000</value> <!-- Set it to 10min to allow enough time for clean shutdown of containers --> </property> - Yarn 机架识别功能不是必需的,不会改变 Samza 主机关联的行为。但是,如果在集群中配置了机架识别,请确保 DNSToSwitchMapping 实现非常稳健。任何故障都可能导致容器请求返回到 defaultRack。这将导致 ContainerRequests 与首选主机不匹配,这将降低主机关联性。
配置 Samza 作业以使用Host Affinity
任何有状态的 Samza 工作都可以通过设置 yarn.samza.host-affinity.enabled 为 true 来利用此功能来减少其状态存储的平均恢复时间(MTTR)。
yarn.samza.host-affinity.enabled=true # Default: false为无状态 Samza 作业启用此功能不应对作业产生任何不利影响。
主机关联保证
正如您所观察到的,由于 Yarn 群集中的 varibale 载入分布,主机关联性无法一直保证。因此,这是 Samza 提供的尽力而为的政策。但是,某些情况值得一提的是,这些保证可能难以实现或不适用。
- 当容器数量或容器任务分配在连续的应用程序运行时发生更改时 - 我们可能能够为分区子集重新使用本地状态。目前,作业协调员没有任何逻辑来智能地处理容器中任务的分区。与容器的自动缩放相关的操作更多涉及。但是,通过任务容器映射,对于典型的容器计数调整,这将更有效。
- 当 SystemStreamPartitionGrouper 在连续的应用程序运行中发生变化时 - 当用于在容器之间分配分区的分组器逻辑发生变化时,协调器流中的数据(对于 changelog-任务分区分配等)和数据存储变为无效。因此,为了安全起见,我们应该从协调器流中清除所有与状态有关的数据。另一种方法是在重新启动作业之前,在协调器流中覆盖 Task-ChangelogPartition 分配消息和容器位置消息。


更多建议: