


Redis 延迟考虑
2018-08-03 11:14 更新
1. 尽可能使用批量操作:
- mget、hmget而不是get和hget,对于set也是如此。
- lpush向一个list一次性导入多个元素,而不用lset一个个添加
- LRANGE 一次取出一个范围的元素,也不用LINDEX一个个取出
2. 尽可能的把redis和APP SERVER部署在一个网段甚至一台机器。
3. 对于数据量较大的集合,不要轻易进行删除操作,这样会阻塞服务器,一般采用重命名+批量删除的策略:
排序集合:
# Rename the key
newkey = "gc:hashes:" + redis.INCR("gc:index")
redis.RENAME("my.zset.key", newkey)
# Delete members from the sorted set in batche of 100s
while redis.ZCARD(newkey) > 0
redis.ZREMRANGEBYRANK(newkey, 0, 99)
end
集合:
# Rename the key
newkey = "gc:hashes:" + redis.INCR("gc:index")
redis.RENAME("my.set.key", newkey)
# Delete members from the set in batches of 100
cursor = 0
loop
cursor, members = redis.SSCAN(newkey, cursor, "COUNT", 100)
if size of members > 0
redis.SREM(newkey, members)
end
if cursor == 0
break
end
end
列表:
# Rename the key
newkey = "gc:hashes:" + redis.INCR("gc:index")
redis.RENAME("my.list.key", newkey)
# Trim off elements in batche of 100s
while redis.LLEN(newkey) > 0
redis.LTRIM(newkey, 0, -99)
end
Hash:
# Rename the key
newkey = "gc:hashes:" + redis.INCR( "gc:index" )
redis.RENAME("my.hash.key", newkey)
# Delete fields from the hash in batche of 100s
cursor = 0
loop
cursor, hash_keys = redis.HSCAN(newkey, cursor, "COUNT", 100)
if hash_keys count > 0
redis.HDEL(newkey, hash_keys)
end
if cursor == 0
break
end
end
4. 尽可能使用不要超过1M大小的kv。
5. 减少对大数据集的高时间复杂度的操作:根据复杂度计算,如下命令可以优化:

6. 尽可能使用pipeline操作:一次性的发送命令比一个个发要减少网络延迟和单个处理开销。一个性能测试结果为(注意并不是pipeline越大效率越高,注意最后一个测试结果) :
logger@BIGD1TMP:~> redis-benchmark -q -r 100000 -n 1000000 -c 50
PING_INLINE: 90155.07 requests per second
PING_BULK: 92302.02 requests per second
SET: 85070.18 requests per second
GET: 86184.61 requests per second
logger@BIGD1TMP:~> redis-benchmark -q -r 100000 -n 1000000 -c 50 -P 10
PING_INLINE: 558035.69 requests per second
PING_BULK: 668002.69 requests per second
SET: 275027.50 requests per second
GET: 376647.84 requests per second
logger@BIGD1TMP:~> redis-benchmark -q -r 100000 -n 1000000 -c 50 -P 20
PING_INLINE: 705716.25 requests per second
PING_BULK: 869565.25 requests per second
SET: 343406.59 requests per second
GET: 459347.72 requests per second
logger@BIGD1TMP:~> redis-benchmark -q -r 100000 -n 1000000 -c 50 -P 50
PING_INLINE: 940733.81 requests per second
PING_BULK: 1317523.00 requests per second
SET: 380807.31 requests per second
GET: 523834.47 requests per second
logger@BIGD1TMP:~> redis-benchmark -q -r 100000 -n 1000000 -c 50 -P 100
PING_INLINE: 999000.94 requests per second
PING_BULK: 1440922.12 requests per second
SET: 386996.88 requests per second
GET: 602046.94 requests per second
logger@BIGD1TMP:~> redis-benchmark -q -r 100000 -n 1000000 -c 50 -P 200
PING_INLINE: 1078748.62 requests per second
PING_BULK: 1381215.50 requests per second
SET: 379218.81 requests per second
GET: 537634.38 requests per second
一个场景是一个购物车的设计,一般的设计思路是:
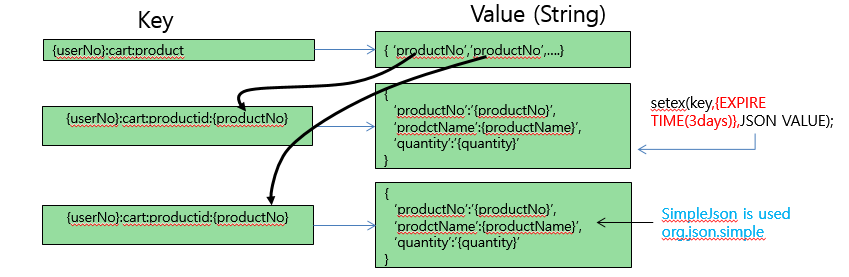
在获取购物车内部货品时,不使用pipeline会很低效:
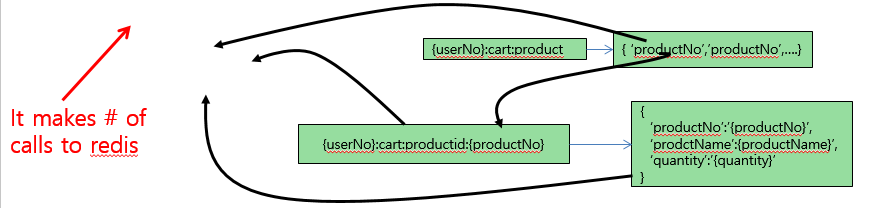
可以修改为:

7. 如果出现频繁对string进行append操作,则请使用list进行push操作,取出时使用pop。这样避免string频繁分配内存导致的延时。
8. 如果要sort的集合非常大的话排序就会消耗很长时间。由于redis单线程的,所以长时间的排序操作会阻塞其他client的 请求。解决办法是通过主从复制机制将数据复制到多个slave上。然后我们只在slave上做排序操作。把可能的对排序结果缓存。另外就是一个方案是就是采用sorted set对需要按某个顺序访问的集合建立索引。
以上内容是否对您有帮助:


更多建议: