


Python3爬虫获取豆瓣读书数据

本文转载至知乎ID:Charles(白露未晞)知乎个人专栏
下载W3Cschool手机App,0基础随时随地学编程>>戳此了解
导语
利用Python爬取豆瓣读书的一些数据,并对这些数据做一定的分析。
标题可能改成类似“大数据时代如何科学有效地阅读”这样的题目更加引入瞩目吧,hhhhh。
——>
对过程不感兴趣的同学可以直接下拉到最后看结果~~~
相关文件
百度网盘下载链接: https://pan.baidu.com/s/1N8mWiDtf7WeBt-lxVPL1_g
密码: s4xb
主要思路
利用Python的requests模块和beautifulsoup模块来爬取豆瓣读书的数据,并对这些数据做一定的分析。
爬取的数据包括:
豆瓣图书各个分类中所有书籍的'书名', '作者/译者', '出版信息', '星级', '评分', '评价人数', '简介', '相应的豆瓣链接'。
例如:
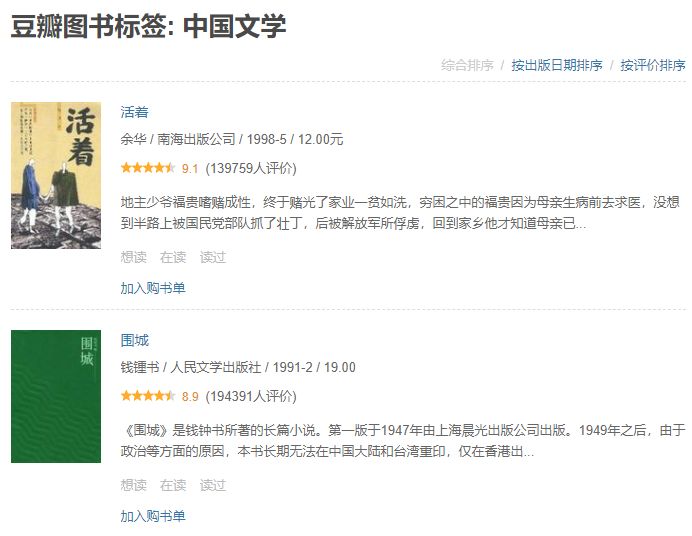
同时,通过爬取的豆瓣链接对具体书籍的质量做一定的分析,分析包括:
制作热评词云、对热评进行简单的情感分析。
有需要者可自行修改源代码进行更多的数据分析。
说明
(1)因为豆瓣严格限制爬虫,且实际使用时也没有必要爬取所有分类的图书资料,给豆瓣服务器带来不必要的压力,因此我给出的源代码一次仅能爬取一个小类的图书资料,且为单进程。
(2)在相关文件中,本人已经提供了爬取到的上百个分类的几万本图书数据,供有需要者参考。
PS:
建筑、漫画、日本漫画、耽美这四个小类的数据写入excel时抛出异常,因此暂时无法提供数据。
开发工具
Python版本:3.5.4
相关模块:
requests模块、jieba模块、BeautifulSoup模块、openpyxl模块、matplotlib模块、wordcloud模块、snownlp模块以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
前期准备
以chrome浏览器为例。
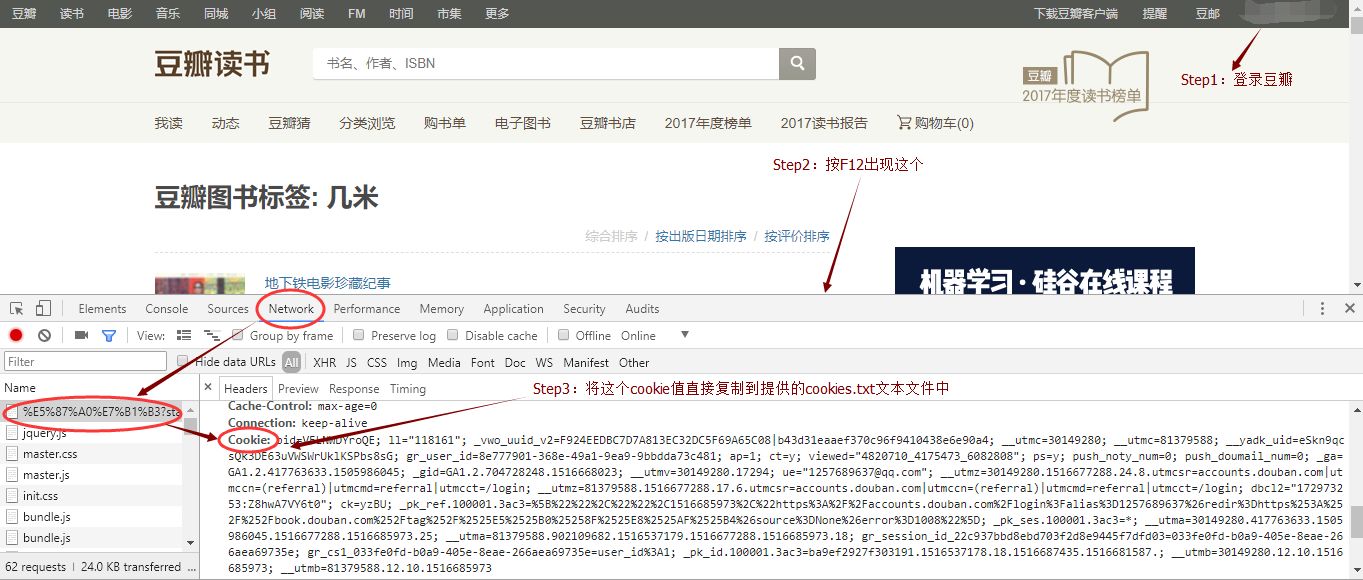
使用演示1
演示内容:
爬取某个小类所有相关书籍基本信息。
截图如下:
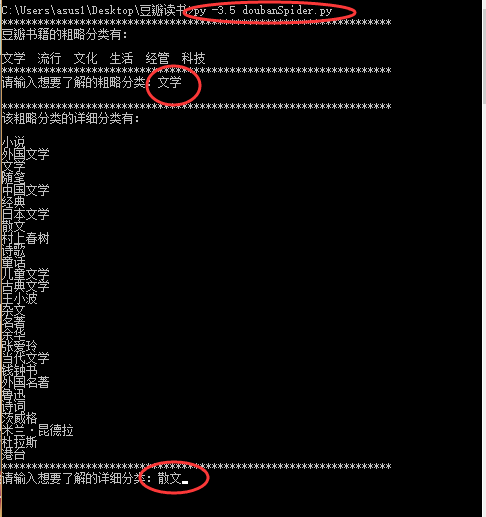
按照提示进行输入,输入完成后按下回车键即可。
最后结果将保存在results文件夹中:
结果展示1
分析内容为:
挑选其中几类利用excel的统计功能对获得的数据进行简单的分析。
以名著类为例:
评分分布图:
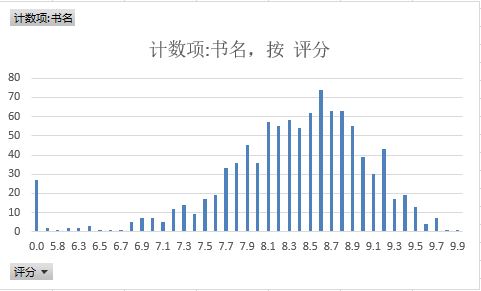
评分Top10:
世界童话名著连环画
坂田荣男围棋全集(共12册)
世界文学名著连环画 欧美部分(全十册)
三国演义
细说红楼梦 1-80回
世界文学名著连环画(亚非部分全五册)
算术探索
三国演义(绘画本1-5)
四大名著(套装全4册)
红楼梦
热度(评论人数)Top10:
围城
不能承受的生命之轻
红楼梦
百年孤独
简爱
傲慢与偏见
飘
月亮和六便士
边城
霍乱时期的爱情
更多内容请自行下载相关文件中提供的数据根据个人喜好进行分析选择。
使用演示2
演示内容为:
对具体书籍制作豆瓣热评词云并对豆瓣热评进行简单的情感分析。
截图如下:

链接地址都保存到了excel表中,复制粘贴即可。
如下图所示:
结果展示2
分析内容为:
爬取豆瓣读书中具体一本书的前20页短评,并制作成词云,同时对这些短评进行简单的情感分析。
以《统计学习方法》为例:
词云:

情感分析:

数值较大说明情感偏积极,否则情感偏消极。
更多
本人不是专业做数据分析的~~~
所以分析的有些稚嫩~~~
欢迎专业人士指导补充~~~


更多建议: