


Pipeline 扩展共享库
由于Pipeline在一个组织中越来越多的项目被采用,普遍的模式很可能会出现。通常,在各种项目之间共享Pipeline的部分是有用的,以减少冗余并保持代码“DRY” 。
Pipeline支持创建“共享库”,可以在外部源代码控制存储库中定义并加载到现有的Pipeline中。
定义共享库
共享库使用名称,源代码检索方法(如SCM)以及可选的默认版本进行定义。该名称应该是一个简短的标识符,因为它将在脚本中使用。
该版本可以被该SCM所了解; 例如,分支,标签和提交hashes都为Git工作。您还可以声明脚本是否需要显式请求该库(详见下文),或默认情况下是否存在。此外,如果您在Jenkins配置中指定版本,则可以阻止脚本选择不同的版本。
指定SCM的最佳方法是使用已经特别更新的SCM插件,以支持新的API来检出任意命名版本(现代SCM选项)。在撰写本文时,最新版本的Git和Subversion插件支持此模式; 其他人应该遵循。
如果您的SCM插件尚未集成,则可以选择Legacy SCM并选择所提供的任何内容。在这种情况下,您需要${library.yourLibName.version}在SCM的配置中包含 某处,以便在结帐时插件将扩展此变量以选择所需的版本。例如,对于Subversion,您可以将Repository URL设置为https://svnserver/project/${library.yourLibName.version},然后使用诸如trunkor branches/dev或之类的版本tags/1.0
目录结构
共享库存储库的目录结构如下所示:
(root)
+- src # Groovy source files
| +- org
| +- foo
| +- Bar.groovy # for org.foo.Bar class
+- vars
| +- foo.groovy # for global 'foo' variable
| +- foo.txt # help for 'foo' variable
+- resources # resource files (external libraries only)
| +- org
| +- foo
| +- bar.json # static helper data for org.foo.Bar该src目录应该像标准的Java源目录结构。执行Pipeline时,该目录将添加到类路径中。
该vars目录托管定义可从Pipeline访问的全局变量的脚本。通常,每个*.groovy文件的基本名称应该是Groovy(〜Java)标识符camelCased。匹配*.txt(如果存在)可以包含通过系统配置的标记格式化程序处理的文档(所以可能真的是HTML,Markdown等,尽管txt需要扩展)。
这些目录中的Groovy源文件与Scripted Pipeline中的“CPS转换”相同。
甲resources目录允许libraryResource从外部库中使用步骤来加载相关联的非Groovy文件。目前内部库不支持此功能。
保留根目录下的其他目录,以备将来进行增强
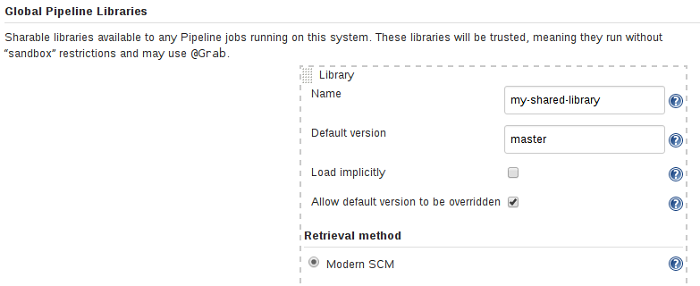
全球共享库
根据用例,有几个可以定义共享库的地方。管理Jenkins»配置系统»全局Pipeline库 可以配置所需的许多库。

由于这些库将全局可用,系统中的任何Pipeline都可以利用这些库中实现的功能。
这些库被认为是“受信任的”:他们可以在Java,Groovy,Jenkins内部API,Jenkins插件或第三方库中运行任何方法。这允许您定义将各个不安全的API封装在更高级别的包装器中的库,以便从任何Pipeline使用。请注意,任何能够将提交到该SCM存储库的人都可以无限制地访问Jenkins。您需要总体/ RunScripts权限来配置这些库(通常这将授予Jenkins管理员)。
文件夹级共享库
创建的任何文件夹可以具有与其关联的共享库。此机制允许将特定库范围限定为文件夹或子文件夹内的所有Pipeline。
基于文件夹的库不被认为是“受信任的”:它们像Groovy sandbox 一样运行,就像典型的Pipeline一样。
自动共享库
其他插件可能会添加在运行中定义库的方法。例如, GitHub分支源插件提供了一个“GitHub组织文件夹”项,它允许脚本使用不受信任的库,例如github.com/someorg/somerepo没有任何其他配置。在这种情况下,指定的GitHub存储库将从master 分支中使用匿名检出进行加载。
使用库
标记为加载的共享库隐式允许Pipeline立即使用由任何此类库定义的类或全局变量。要访问其他共享库,Jenkinsfile需要使用@Library注释,指定库的名称:
@Library('my-shared-library') _
/* Using a version specifier, such as branch, tag, etc */
@Library('my-shared-library@1.0') _
/* Accessing multiple libraries with one statement */
@Library(['my-shared-library', 'otherlib@abc1234']) _注释可以在脚本中的任何地方,Groovy允许注释。当引用类库(包含src/目录)时,通常会在import语句上注释:
@Library('somelib')
import com.mycorp.pipeline.somelib.UsefulClass对于仅定义全局变量(vars/)的共享库或 Jenkinsfile仅需要全局变量的 共享库,注释 模式@Library('my-shared-library') _可能有助于保持代码简洁。实质上,import该符号不是注释不必要的语句_。
不推荐import使用全局变量/函数,因为这将强制编译器解释字段和方法,static 即使它们是实例。在这种情况下,Groovy编译器可能会产生混乱的错误消息。在编译脚本之前,在开始执行之前解析和加载库。这允许Groovy编译器了解在静态类型检查中使用的符号的含义,并允许它们在脚本中的类型声明中使用,例如:
@Library('somelib')
import com.mycorp.pipeline.somelib.Helper
int useSomeLib(Helper helper) {
helper.prepare()
return helper.count()
}
echo useSomeLib(new Helper('some text'))然而,全局变量在运行时解决。
动态加载库
从2.7版Pipeline:共享Groovy库插件,有一个新的选项,用于在脚本中加载(非隐式)库:一个在构建期间的任何时间动态library加载库的步骤。
如果您只对使用全局变量/函数感兴趣(从vars/目录中),语法非常简单:
library 'my-shared-library'此后,脚本中可以访问该库中的任何全局变量。
从src/目录中使用类也是可能的,但是比较棘手。而在@Library编译之前,注释准备脚本的“classpath”,在library遇到步骤时,脚本已经被编译。因此,您不能import或以其他方式“静态地”引用库中的类型。
但是,您可以动态地使用库类(无类型检查),从library步骤的返回值通过完全限定名称访问它们。 static可以使用类似Java的语法来调用方法:
library('my-shared-library').com.mycorp.pipeline.Utils.someStaticMethod()您还可以访问static字段,并调用构造函数,就像它们是指定的static方法一样new:
def useSomeLib(helper) { // dynamic: cannot declare as Helper
helper.prepare()
return helper.count()
}
def lib = library('my-shared-library').com.mycorp.pipeline // preselect the package
echo useSomeLib(lib.Helper.new(lib.Constants.SOME_TEXT))库版本
例如,当勾选“加载隐式”时,或者如果Pipeline仅以名称引用库,则使用配置的共享库的“默认版本” @Library('my-shared-library') _。如果“默认版本” 没有定义,Pipeline必须指定一个版本,例如 @Library('my-shared-library@master') _。
如果在共享库的配置中启用了“允许默认版本被覆盖”,则@Library注释也可以覆盖为库定义的默认版本。这样还可以在必要时从不同的版本加载带有“负载加载”的库。
使用该library步骤时,您还可以指定一个版本:
library 'my-shared-library@master'由于这是一个常规步骤,所以该版本可以 与注释一样计算而不是常量; 例如:
library "my-shared-library@$BRANCH_NAME"将使用与多分支相同的SCM分支来加载库Jenkinsfile。另一个例子,你可以通过参数选择一个库:
properties([parameters([string(name: 'LIB_VERSION', defaultValue: 'master')])])
library "my-shared-library@${params.LIB_VERSION}"请注意,该library步骤可能不会用于覆盖隐式加载库的版本。它在脚本启动时已经加载,给定名称的库可能不会被加载两次。
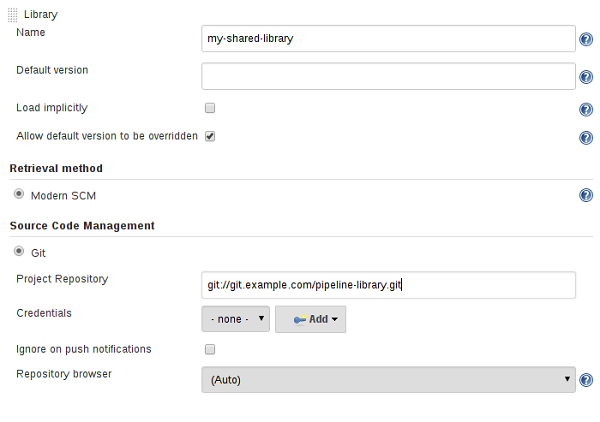
检索方法
指定SCM的最佳方法是使用已经特别更新的SCM插件,以支持新的API来检出任意命名版本(现代SCM选项)。在撰写本文时,Git和Subversion插件的最新版本支持此模式。
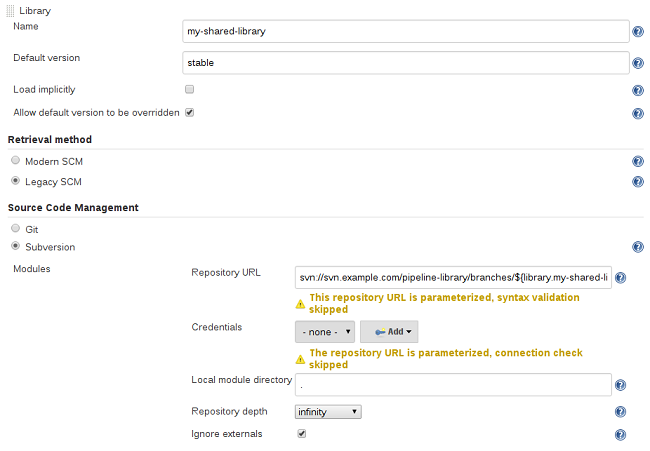
传统SCM
尚未更新以支持共享库所需的较新功能的SCM插件仍可通过Legacy SCM选项使用。在这种情况下,包括${library.yourlibrarynamehere.version}可以为该特定SCM插件配置branch / tag / ref的任何位置。这可以确保在检索库的源代码期间,SCM插件将扩展此变量以检出库的相应版本。
动态检索
如果您仅@在library步骤中指定库名称(可选地,随后使用版本),Jenkins将查找该名称的预配置库。(或者在github.com/owner/repo自动库的情况下,它将加载。)
但是您也可以动态地指定检索方法,在这种情况下,不需要在Jenkins中预定义库。这是一个例子:
library identifier: 'custom-lib@master', retriever: modernSCM(
[$class: 'GitSCMSource',
remote: 'git@git.mycorp.com:my-jenkins-utils.git',
credentialsId: 'my-private-key'])为了您的SCM的精确语法,最好参考流水线语法。
请注意,在这些情况下必须指定库版本。
Writing libraries
在基层,任何有效的 Groovy代码 都可以使用。不同的数据结构,实用方法等,如:
// src/org/foo/Point.groovy
package org.foo;
// point in 3D space
class Point {
float x,y,z;
}访问步骤
库类不能直接调用诸如shor的步骤git。然而,它们可以实现除封闭类之外的方法,这些方法又调用Pipeline步骤,例如:
// src/org/foo/Zot.groovy
package org.foo;
def checkOutFrom(repo) {
git url: "git@github.com:jenkinsci/${repo}"
}然后可以从脚本Pipeline中调用它:
def z = new org.foo.Zot()
z.checkOutFrom(repo)这种做法有局限性; 例如,它阻止了超类的声明。
或者,一组steps可以显式传递给库类,构造函数或只是一种方法:
package org.foo
class Utilities implements Serializable {
def steps
Utilities(steps) {this.steps = steps}
def mvn(args) {
steps.sh "${steps.tool 'Maven'}/bin/mvn -o ${args}"
}
}当在类上保存状态时,如上面所述,类必须实现 Serializable接口。这样可确保使用该类的Pipeline,如下面的示例所示,可以在Jenkins中正确挂起并恢复。
@Library('utils') import org.foo.Utilities
def utils = new Utilities(steps)
node {
utils.mvn 'clean package'
}如果库需要访问全局变量,例如env,那些应该以类似的方式显式传递给库类或方法。
而不是将许多变量从脚本Pipeline传递到库中,
package org.foo
class Utilities {
static def mvn(script, args) {
script.sh "${script.tool 'Maven'}/bin/mvn -s ${script.env.HOME}/jenkins.xml -o ${args}"
}
}上面的示例显示了脚本被传递到一个static方法,从脚本Pipeline调用如下:
@Library('utils') import static org.foo.Utilities.*
node {
mvn this, 'clean package'
}定义全局变量
在内部,vars目录中的脚本作为单例按需实例化。这允许在单个.groovy文件中定义多个方法或属性,这些文件彼此交互,例如:
// vars/acme.groovy
def setName(value) {
name = value
}
def getName() {
name
}
def caution(message) {
echo "Hello, ${name}! CAUTION: ${message}"
}在上面,name不是指一个字段(即使你把它写成this.name!),而是一个根据需要创建的条目Script.binding。要清楚你要存储什么类型的什么数据,你可以改为提供一个明确的类声明(类名称应符合的文件名前缀,如果只能调用Pipeline的步骤steps或this传递给类或方法,与src上述课程一样):
// vars/acme.groovy
class acme implements Serializable {
private String name
def setName(value) {
name = value
}
def getName() {
name
}
def caution(message) {
echo "Hello, ${name}! CAUTION: ${message}"
}
}然后,Pipeline可以调用将在acme对象上定义的这些方法 :
acme.name = 'Alice'
echo acme.name /* prints: 'Alice' */
acme.caution 'The queen is angry!' /* prints: 'Hello, Alice. CAUTION: The queen is angry!' */温习提示:在Jenkins加载并使用该库作为成功的Pipeline运行的一部分后,共享库中定义的变量将仅显示在“ 全局变量参考”(在“ Pipeline语法”下)。
定义步骤
共享库还可以定义与内置步骤类似的全局变量,例如sh或git。共享库中定义的全局变量必须使用所有小写或“camelCase”命名,以便由Pipeline正确加载。
例如,要定义sayHello,vars/sayHello.groovy 应该创建文件,并应该实现一个call方法。该call方法允许以类似于以下步骤的方式调用全局变量:
// vars/sayHello.groovy
def call(String name = 'human') {
// Any valid steps can be called from this code, just like in other
// Scripted Pipeline
echo "Hello, ${name}."
}然后,Pipeline将能够引用并调用此变量:
sayHello 'Joe'
sayHello() /* invoke with default arguments */如果调用一个块,该call方法将收到一个 Closure。应明确界定类型,以澄清步骤的意图,例如:
// vars/windows.groovy
def call(Closure body) {
node('windows') {
body()
}
}然后,Pipeline可以像接受一个块的任何内置步骤一样使用此变量:
windows {
bat "cmd /?"
}定义更结构化的DSL
如果您有大量类似的Pipeline,则全局变量机制提供了一个方便的工具来构建更高级别的DSL来捕获相似性。例如,所有的插件Jenkins构建和以同样的方式进行测试,所以我们可以写一个名为步 buildPlugin:
// vars/buildPlugin.groovy
def call(body) {
// evaluate the body block, and collect configuration into the object
def config = [:]
body.resolveStrategy = Closure.DELEGATE_FIRST
body.delegate = config
body()
// now build, based on the configuration provided
node {
git url: "https://github.com/jenkinsci/${config.name}-plugin.git"
sh "mvn install"
mail to: "...", subject: "${config.name} plugin build", body: "..."
}
}假设脚本已被加载为 全局共享库或 文件夹级共享库 ,结果Jenkinsfile将会更加简单:
Jenkinsfile (Scripted Pipeline)
buildPlugin {
name = 'git'
}使用第三方库
通过使用注释,可以使用通常位于Maven Central中的第三方Java库 从受信任的库代码中使用@Grab。 有关详细信息,请参阅 Grape文档,但简单地说:
@Grab('org.apache.commons:commons-math3:3.4.1')
import org.apache.commons.math3.primes.Primes
void parallelize(int count) {
if (!Primes.isPrime(count)) {
error "${count} was not prime"
}
// …
}第三方库默认缓存~/.groovy/grapes/在Jenkins主机上。
资源加载
外部库可以resources/使用libraryResource步骤从目录中加载附件文件。参数是一个相对路径名,类似于Java资源加载:
def request = libraryResource 'com/mycorp/pipeline/somelib/request.json'该文件作为字符串加载,适合传递给某些API或使用保存到工作空间writeFile。
建议使用独特的包装结构,以便您不会意外与另一个库冲突。
预测库更改
如果您使用不受信任的库发现构建中的错误,只需单击Replay链接即可尝试编辑其一个或多个源文件,并查看生成的构建是否按预期方式运行。一旦您对结果感到满意,请从构建状态页面执行diff链接,并将diff应用于库存储库并提交。
(即使库要求的版本是分支,而不是像标签一样的固定版本,重播的构建将使用与原始版本完全相同的修订版本:库源将不会被重新签出。)
受信任的库不支持重放。Replay中目前不支持修改资源文件。


更多建议: