数据结构主要有DataSet,DataRow两种
分别对应数据库的表与行
DataSet是DataRow的集合
DataSet通常由AnylineService.query()或AnylineService.cache()返回
DataRow通常由AnylineService.queryRow()或AnylineService.cacheRow()返回
数据结构:DataRow
DataRow对应数据库中的一行数据内部是一个Map结构,Map的key对应了表的列名,一般通过anyline-config.IS_UPPER_KEY=true来设置返回值以大写key存储
DataRow提供了一些默认的数据操作方法
| public Object get(String key) | 提取DataRow中的值 |
| public boolean getBoolean(String key) | 提取DataRow中的值并转换成Boolean值 |
| public boolean getBoolean(String key, boolean def) | 提取DataRow中的值并转换成Boolean值,如果没有值则默认为def |
| public Date getDate(String key, String def) | 提取DataRow中的值并转换成Date类型,如果没有值则默认为def |
| public Date getDate(String key, Date def) | 提取DataRow中的值并转换成Date类型,如果没有值则默认为def |
| public BigDecimal getDecimal(String key) | 提取DataRow中的值并转换成BigDecimal类型 |
| public BigDecimal getDecimal(String key, BigDecimal def) | 提取DataRow中的值并转换成BigDecimal类型,如果没有值则默认为def |
| public BigDecimal getDecimal(String key, double def) | 提取DataRow中的值并转换成BigDecimal类型,如果没有值则默认为def |
| public int getInt(String key) | 提取DataRow中的值并转换成Int类型,如果没有值则默认为0 |
| public int getInt(String key, int def) | 提取DataRow中的值并转换成int类型,如果没有值则默认为def |
| public long getLong(String key) | 提取DataRow中的值并转换成long类型,如果没有值则默认为0 |
| public long getLong(String key, long def) | 提取DataRow中的值并转换成long类型,如果没有值则默认为def |
| public DataRow getRow(String key) | 获取DataRow中的值并转换成DataRow,如果值不是DataRow类型则返回null |
| public DataSet getSet(String key) | 获取DataRow中的值并转换成DataSet,如果值不是DataSet类型则返回null |
| public String getPrimaryKey() | 获取主键 |
| public String getPrimaryKeys() | 攻取主键列表,复合主键时使用 |
| public DataRow addPrimaryKey(String ... pks) | 添加主键,DataRow默认以ID作主键,调用以上方法可以在ID基础上添加多个主键。
在AnylineService.save(DataRow)时会根据主键来判断insert还是update
applyContainer:设置主键时,是否同时应用到父级容器DataSet上 |
| public DataRow addPrimaryKey(boolean applyContainer, Collection pks) |
| public DataRow addPrimaryKey(boolean applyContainer, String ... pks) |
| public DataRow addAllUpdateColumns() | 将所有列添加入保存范围
AnylineService.save(DataRow)如果是update操作,则只会update值修改过和列
如果要强制upate所有列,需要调用以上方法 |
| public DataRow clearUpdateColumns() | 清除所有需要更新的列(只是标记所有列不需要更新,并不清空值) |
| public boolean checkRequired(String ... keys) | 检测指定的列中是否有空值 |
| public DataRow clearEmpty() | 删除值为空的条目,相当于调用Map.remove(key) |
| public DataRow clearNull() | 删除值为null的条目 |
| public boolean containsKey(String key) | 是否包含指定的key |
| public DataRow copy(DataRow data, String ... keys) | 将data中对应的key的值存入当前对象,如果有重复的key以data中的值为准 |
| public T entity(Class clazz) | 将普通的Java对象转换成DataRow |
| public DataRow formatDate(String format, String ... cols) | 格式化指定列的日期格式 |
| public DataRow formatNumber(String format, String ... cols) | 格式化指定列的数字格式 |
| public Object getPrimaryValue() | 获取主键值 |
| public Object getPrimaryValues() | 获取主键值,复合主键时使用 |
| public boolean hasValue(String key) | return get(key) != null; |
| public boolean isEmpty(String key) | 指定列的值是否(不)为空(null) |
| public boolean isNotEmpty(String key) |
| public boolean isNull(String key) |
| public boolean isNotNull(String key) |
| public boolean isExpire() | 从创建对象到现在是否超过指定时间,配合setExpire(int millisecond)使用 |
| public boolean isExpire(int millisecond) | 从创建对象到现在是否超过指定时间 |
| public DataRow merge(DataRow row, boolean over) | 将row中的数据合并到当前DataRow
over:key相同时是否覆盖当前DataRow中的值 |
| public DataRow merge(DataRow row |
| public Object put(String key, Object value) | 类似于Map.put()
pk:是否将当前key作为主键
override:如果当前DataRow中已存在key值是否覆盖原来的值 |
| public Object put(String key, Object value, boolean pk) |
| public Object put(String key, Object value, boolean pk, boolean override) |
| public void setUpdateEmptyColumn(boolean updateEmptyColumn) | 设置是否更新值为空的列 |
| public void setUpdateNullColumn(boolean updateNullColumn) | 设置是否更新值为null的列 |
| public String toJSON() | 转换成json格式字符 |
| public String toXML() | 转换成xml格式字符
border:是否添加xml外层标签包裹 order:是否需要排序后转换 |
| public String toXML(boolean border, boolean order) |
| public DataRow toLowerKey(String ... keys) | 将指定的key转换成小(大)写,如果不指定则转换全部key
转换的是key而不是value |
| public DataRow toUpperKey(String ... keys) |
| public DataRow setExpires(int millisecond) | 设置过期时间,配合isExpires()使用 |
数据结构:DataSet
DataSet对应数据库中的多行数据,是一个DataRow集合,内部是一个Collection结构
DataSet提供了一些默认的数据操作方法
| public boolean add(Object e) | 添加一行,并将e转换成DataRow格式 |
| public boolean addAll(Collection c) | 添加多行 |
| public DataSet addRow(DataRow row) | 添加一行,只有当row != null时执行添加 |
| public DataSet addRow(int idx, DataRow row) | 在idx位置插入一行 |
| public DataSet addPrimaryKey(boolean applyItem, Collection pks) | 添加主键,参考DataRow |
| public DataSet addPrimaryKey(boolean applyItem, String ... pks) | applyItem:是否应用到集合中的DataRow 默认true |
| public DataSet intersection(DataSet set, String ... keys) | 根据keys取set与当前DataSet的交集,返回结果为新生成的DataSet对象 |
| public DataSet and(DataSet set, String ... keys) |
| public DataSet difference(DataSet set, String ... keys) | 根据keys取set与当前DataSet的差集,返回结果为新生成的DataSet对象 |
| public DataSet asc(final String ... keys) | 根据keys值排序 |
| public DataSet order(final String ... keys) | 根据keys值排序(正序) |
| public DataSet desc(final String ... keys) | 根据keys值排序 |
| public BigDecimal avg(int top, String key) | 从第0行到top行,计算key列的平均值,空值不参与除法 |
| public BigDecimal avg(String key) | 计算key列的平均值 |
| public boolean checkRequired(String ... keys) | 集合中的DataRow是否keys值都不为空 |
| public void clear() | 清空集合中的所有条目 |
| public String concat(String key, String connector) | 提取集合中所有条目的key值,并以connector拼接 |
| public String concat(String key) | 提取集合中所有条目的key值,并以","拼接 |
| public String concatNvl(String key) | 提取集合中所有条目的key值,并以","拼接,如果有null值则以""代替 |
| public String concatNvl(String key, String connector) | 提取集合中所有条目的key值,并以connector拼接,如果有null值则以""代替 |
| public String concatWithoutEmpty(String key) | 提取集合中所有条目的key值,并以","拼接,如果值为空则略过 |
| public String concatWithoutEmpty(String key, String connector) | 提取集合中所有条目的key值,并以connector拼接,如果值为空则略过 |
| public String concatWithoutNull(String key) | 提取集合中所有条目的key值,并以","拼接,如果值为null则略过 |
| public String concatWithoutNull(String key, String connector) | 提取集合中所有条目的key值,并以connector拼接,如果值为null则略过 |
| public boolean contains(DataRow row, String ... keys) | 是否包含row,检测指定keys的value值相同则认为包含
如果未指定keys,则只检测主键值 |
| public DataSet cut(int begin) | 截取begin到最后一行 |
| public DataSet cut(int begin, int end) | 截取begin到end行 |
| public DataSet dispatchItems(String field, boolean recursion, DataSet items, String ... keys) | 从items中按相应的key提取数据 存入集合中的DataRow
recursion:是否递归执行
dispatchItems("children",items, "PARENT_ID")
dispatchItems("children",items, "ID:PARENT_ID")
参考经典场景一节中的示例 |
| public DataSet dispatchItems(String field,DataSet items, String ... keys) |
| public DataSet dispatchItems(DataSet items, String ... keys) |
| public DataSet dispatchItems(boolean recursion, String ... keys) |
| public DataSet dispatchItems(String field, boolean recursion, String ... keys) |
| public DataSet unique(String ... keys) | 根据keys值提取集合中不重复的子集,返回结果为新生成的DataSet |
| public DataSet distinct(String... keys) | 根据keys值提取集合中不重复的子集,返回结果为新生成的DataSet |
| public List getDistinctStrings(String key) | 提取指定列中不重复的值的集合 |
| public List fetchDistinctValue(String key) | 提取指定列中不重复的值的集合 |
| public List fetchValues(String key) | 提取key列的值,包含重复值 |
| public DataSet filter(int begin, int end, String key, String value) | 取begin行到end行中,key值=value的子集 |
| public DataSet formatDate(String format, String ... cols) | 将集合中DataRow的cols列格式化 |
| public DataSet formatNumber(String format, String ... cols) | 将集合中DataRow的cols列格式化 |
| public Object get(int index, String key) | 取第index个条目的key值 |
| public BigDecimal getDecimal(int idx, String key) |
| public BigDecimal getDecimal(int idx, String key, double def) |
| public BigDecimal getDecimal(int idx, String key, BigDecimal def) |
| public int getInt(int idx, String key) |
| public int getInt(int idx, String key, int def) |
| public double getDouble(int idx, String key, double def) |
| public long getLong(int idx, String key) |
| public long getLong(int idx, String key, long def) |
| public Date getDate(int idx, String key) |
| public Date getDate(int idx, String key, Date def) |
| public Date getDate(int idx, String key, String def) |
| public String getEscapeString(int index, String key) | 取第index行key值并进行escapse编码 |
| public String getDoubleEscapeString(int index, String key) { | 取第index行key值并进行两次escapse编码 |
| public PageNavi getNavi() | 分页信息,查询方法有分页时有效 |
| public DataRow getRow(int index) | 提取第index行 |
| public DataRow getRow(int begin, String... params) | 从第begin行开始 key=value的条目
getRow(0,"NAME","ZHANG"); |
| public DataRow getRow(int begin, String... params) | 从第begin行开始 key=value的条目
getRow(0,"NAME","ZHANG","SEX","1"); |
| public DataSet getRows(int fr, int to) | 提取从fr行到to行的子集 |
| public DataSet getRows(int begin, int qty, String... params) | 根据条件从第begin行开始取最多qty行
getRows(0,10,key1,value1,key2:value2,key3,value3); |
| public DataSet getRows(String... params) | 从第0开始 |
| public DataSet getRows(int begin, String... params) |
| public List getStringsWithoutEmpty(String key) |
| public List getStringsWithoutNull(String key) |
| public DataSet group(String ... keys) | 按keys分组,参与经典场景中的示例 |
| public boolean isEmpty() | 集合是否为空 |
| public boolean isExpire(int millisecond) | 从创建到现在是否超过millisecond毫秒 |
| public DataRow max(String key){ | key对应的value最大的一行 |
| public DataRow min(String key) | key对应的value最小的一行 |
| public BigDecimal maxDecimal(int top, String key) | 从第0行到top行中key列最大值 |
| public BigDecimal maxDecimal(String key) | 集合中key列最大值 |
| public BigDecimal minDecimal(int top, String key) | 从第0行到top行中key列最小值 |
| public BigDecimal minDecimal(String key) | 集合中key列最小值 |
| public double maxDouble(int top, String key) | 从第0行到top行中key列最大值 |
| public double maxDouble(String key) | 集合中key列最大值 |
| public double minDouble(int top, String key) | 从第0行到top行中key列最小值 |
| public double minDouble(String key) | 集合中key列最小值 |
| public int maxInt(int top, String key) | 从第0行到top行中key列最大值 |
| public int maxInt(String key) | 集合中key列最大值 |
| public int minInt(int top, String key) | 从第0行到top行中key列最小值 |
| public int minInt(String key) | 集合中key列最小值 |
| public DataSet or(DataSet set, String ... keys) | 合并set与当前DataSet,按keys去重,如果没有指定keys,则按主键去重 |
| public DataSet union(DataSet set, String ... keys) | 合并set与当前DataSet,按keys去重,如果没有指定keys,则按主键去重 |
| public DataSet unionAll(DataSet set) | 合并set与当前DataSet,不去重 |
| public DataRow random() | 随机取一行 |
| public DataSet randoms(int qty) | 随机取qty行 |
| public DataSet regex(String key, String regex) | 匹配regex正则的子集 |
| public DataSet regex(String key, String regex, Regular.MATCH_MODE mode) | org.anyline.util.regular.Regular.MATCH_MODE:匹配模式 |
| public String toJSON() | 列表中的数据格式化成json格式 不同与toString |
类SQL操作
DataSet set = new DataSet();
DataSet result = set.select.equals("NAME","ZHANG");
| public DataSet equals(String key, String value) | where key=value |
| public DataSet equalsIgnoreCase(String key, String value) | where key=value,不区分大小写 |
| public DataSet notEquals(String key, String value) | where key != value |
| public DataSet notEqualsIgnoreCase(String key, String value) | where key != value,不区分大小写 |
| public DataSet contains(String key, String value) | where key like ''%value%'' |
| public DataSet like(String key, String pattern) | where key like pattern,与SQL通配符一致 |
| public DataSet startWith(String key, String prefix) | where key like ''prefix%'' |
| public DataSet endWith(String key, String suffix) | where key like ''%suffix'' |
| public DataSet in(String key, String ... values) | where key in(values) |
| public DataSet in(String key, Collection values) | where key in(values) |
| public DataSet inIgnoreCase(String key, String ... values) | where key in(values),不区分大小写 |
| public DataSet inIgnoreCase(String key, Collection values) | where key in(values),不区分大小写 |
| public DataSet notIn(String key, String ... values) | where key not in(values) |
| public DataSet notIn(String key, Collection values) | where key not in(values) |
| public DataSet notInIgnoreCase(String key, String ... values) | where key not in(values),不区分大小写 |
| public DataSet notInIgnoreCase(String key, Collection values) | where key not in(values),不区分大小写 |
| public DataSet isNull(String key) | where key is null |
| public DataSet isNull(String ... keys) | where key1 is null and key2 is null |
| public DataSet isNotNull(String key) | where key is not null |
| public DataSet isNotNull(String ... keys) | where key1 is not null and key2 is not null |
| public DataSet isEmpty(String key) | where key is empty(null or '') |
| public DataSet isEmpty(String ... keys) | where key1 is empty(null or '') ... |
| public DataSet isNotEmpty(String key) | where key is not empty(null or '') |
| public DataSet isNotEmpty(String ... keys) | where key1 is not empty(null or '') ... |
| public DataSet less(String key, Object value) | where key < value(number,date,string) |
| public DataSet lessEqual(String key, Object value) | where key <= value |
| public DataSet greater(String key, Object value) | where key > value |
| public DataSet greaterEqual(String key, Object value) | where key >= value |
| public DataSet between(String key, Object min, Object max) | where key between min and max |
DataRow
DataRow继承自HashMap, 除了HashMap之外的其他常用函数
public Object put(String key, Object value)
public String getString(String key)
public String getStringNvl(String key, String ... defs)
public int getInt(String key) throws Exception
public int getInt(String key, int def)
public DataSet getSet(String key)
public List<?> getList(String key)
public static DataRow parse(Object obj, String ... keys)
public static DataRow parseJson(String json)
public static DataRow parseXml(String xml)
public static DataRow parseArray(String ... kvs)
public DataRow merge(DataRow row, boolean over)
public DataRow merge(DataRow row)
public DataRow toLowerKey(String ... keys)
public DataRow toUpperKey(String ... keys)
public DataRow formatNumber(String format, String ... cols)
public DataRow formatDate(String format, String ... cols)
public boolean isNull(String key)
public boolean isEmpty(String key)
public <T> T entity(Class<T> clazz)
public boolean hasValue(String key)
public String toJSON()
public String toXML()
public DataRow removeNull(String ... keys)
public DataRow extract(String ... keys)
public DataRow replaceEmpty(String value)
public DataRow replaceEmpty(String value)
public DataRow replaceEmpty(String key, String value)
public DataRow replaceNull(String value)
public DataRow replaceNull(String key, String value)
public String join(String ... keys)
public DataRow add(String key, int value)
public DataRow subtract(String key, int value)
public DataRow multiply(String key, int value)
public DataRow divide(String key, int value)
public Object nvl(String ... keys)
public Object evl(String ... keys)
get(String key)与getString(String key)的区别
get(String key)与Map的get(String key)效果一样
getString(String key)支持表达式getString("${ID}-${NAME}")
关于DataRow parse xml与parse json区别
**json结构相对简单每一对key value可以直接存入DataRow **
{name:zhang,age:20}
对应:
row.put("name","zhang");
row.put("age",20);
但xml比json多了一个attribute,这个attribute不直接存入DataRow
<user id="1"><name>zhang</name></user>
对应:
user.attr("id","1");
user.put("name","zhang");
同样取值时也通过user.attr("id");
关于DataRow中get与getString的区别
DataRow中get是覆盖了父类Map的get
getString在get的基础上增加了复合KEY的支持,如getString("{ID}/{CODE}")
替换DataSet,DataRow中所有空值(null,'')
将所有列中的空值替换成value
public DataSet replaceEmpty(String value)
一维数组转成DataRow 二维数组转成DataSet
通常情况下是把Bean或Map转成DataRow,把Bean和Map的集合转成DataSet
但有些情况下如从excel中读取数据,读取出来的结果是List<List<String>>结构,并没有列名或属性名,只是按下标顺序排列。
这时操作List就比较原始,如分组,排序等都需要重写。
所以可以转成DataSet,这样可以利用DataSet的方法对结果集进行去重、分组等。因为没有属性名所以转换成DataRow后以下标作为keyDataSet set = DataSet.parse(list);
DataRow根据表结构接收参数值
如果有实体类的话,可以根据实体类的属性来接收url中的参数值。
而entity()函数则是根据表结果来接收
DataRow row = entity("{HR_USER}");
DataRow row = entity(TableBuilder.init("HR_USER"));
默认情况下列名与参数名一致。
实际开发中前端提交的数据经常是小驼峰格式,可以在anyline-config.xml配置文件中添加配置camel
camel:表示小驼峰 Camel:表示大驼峰
如表结构ID,NAME,TYPE_CODE,ADDRESS
前端传值id=1&name=zh&typeCode=101
entity()接收加密数据
如果前端提交的参数是加密后的值,需要这样解密
DataRow row = entity("ID:id+");
与getParam("id", true)效果一样
关于DataRow中key的大小写
背景:JAVA从数据库中查出来的数据,封装到DataRow中传给前端显示,显示时需要根据属性名来调用显示内容。属性中经常会有各种不同的命名规则,如userName,UserName这类大小驼峰格式前端还可以分辨,但涉及到一些专用缩写根据不同团体不同人的习惯会出现多种格式,如UserId,UserID,id,Id,ID,所以经常需要统一成大写以避免因大小写造成的问。
所以调用DataRow.put(key,value)时会将key转换成统一格式。在默认情况下key会转换成全大写。
转换规则优先级:
1.DataRow对象自身规则,DataRow 实例化时显式指定。new DataRow(DataRow.KEY_CASE keyCase);KEY_CASE.CONFIG:根据配置类(默认值)KEY_CASE.SRC:原样保存不转换KEY_CASE.UPPER:转大写KEY_CASE.LOWER:转小写KEY_CASE.Camel:下/中划线转成大驼峰KEY_CASE.camel:下/中划线转成小驼峰
2.根据配置类ConfigTable
配置类先加载配置文件anyline-config.xml或统一配置(如nacos等)中的<property key="IS_UPPER_KEY">false</property><property key="IS_LOWER_KEY">false</property>如果没有配置文件则根据默认属性配置类中有两个默认IS_UPPER_KEY = true;IS_LOWER_KEY = false;可以通过调用ConfigTable的静态方式修改以上两个属性ConfigTable.setUpperKey(false);
需要注意的是配置类会定期加载配置文件,所以通过ConfigTable.setUpperKey(false);的效果会被覆盖
在通过DataRow来解析json数据时,同样按以上优先级确认key的大小写。如果要保持原样可以解析时指定key规则
DataRow row = DataRow.parseJson(KEY_CASE.SRC,json);
DataRow key不区分大小写设置
如果设置了keyCase = KEY_CASE.SRC,并且配置文件中设置true
在执行get时不区分key大小写并忽略-与_,但是DataRow中可以put多个key如(USER_ID,userId,UserId),取值是取最后put的值
其他情况在put和get时会强制转换key,所以没有大小写之分
删除空值
new DataSet().removeNull(String ... kyes)
new DataRow().removeNull(String ... kyes)
删除值为null的列,如果不传参数keys或keys.length=0,则检测所有列
new DataSet().removeEmpty(String ... kyes)
new DataRow().removeEmpty(String ... kyes)
删除值为空的列(null或""),如果不传参数keys或keys.length=0,则检测所有列
替换空值
new DataSet().replaceNull(String value)
new DataRow().replaceNull(String value)
new DataSet().replaceNull(String key, String value)
new DataRow().replaceNull(String key, String value)
如果key列的值为null,则替换成value,如果不传参数key则检查所有列
new DataSet().replaceEmpty(String value)
new DataRow().replaceEmpty(String value)
new DataSet().replaceEmpty(String key, String value)
new DataRow().replaceEmpty(String key, String value)
如果key列的值为空(null或""),则替换成value,如果不传参数key则检查所有列
关于DataRow的复合KEY
许多情况下需要从DataRow中取多个值合并显示。如导出excel时地址列需要合并省市区详细地址
DataRow可以取多个值拼接,但DataSet则需要遍历,非常麻烦DataRow提供了复合KEY取值的函数如{ID:1,CODE:A01,NAME:张三}row.getString("{ID}-{CODE}")可以取出 1-A01row.getString("编号:{CODE};姓名:{NAME}")可以取出 编号:A01;姓名:张三
需要注意的是如果其中一个KEY取值为null 或 KEY不存在则以""代替,而不是"null"
类似的在导出EXCEL时指定需要导出的列时也可以使用复合KEY
DataSet
DataSet是DataRow的集合
提供了常用的集合操作以及针对集合中DataRow的操作
一般是由serivce.querys()返回的查询结果集。
DataSet上附加了针对结果集数据二次操作的功能
DataSet构造多级树型结构
表结构类似这样
| ID | BASE_ID | NAME |
| 1 | NULL | 中国 |
| 2 | 1 | 山东 |
| 3 | 2 | 济南 |
| 4 | 2 | 青岛 |
| 5 | 2 | 烟台 |
| 6 | 3 | 历下区 |
| 7 | 3 | 天桥区 |
| 8 | 4 | 市南区 |
| 9 | 4 | 城阳区 |
//先取出完整列表
DataSet set = service.querys("SYS_AREA");
//ID:主键 BASE_ID:表示上一级ID的列名
set.dispatchs(true,true, "ID:BASE_ID");
set.dispatchs("children",true,true, "ID:BASE_ID");
//执行完成后会把每个DataRow中存入当前DataRow的下一级
//这里会生成多个树型结构,一般需要根据ID取出最顶级的DataRow set.getRow("ID",1);
DataSet拆分
有些情况下需要对DataSet分组处理。如:查询出2000个手机号,如果一短信平台一次只能发500个
List<DataSet> list = set.split(set.size()/500);
for(DataSet items:list) {
List<String> mobiles = items.getDistinctStrings("mobile");
}
从列式数据库中取出坐标数据,格式化成地图轨迹需要的数据
轨迹原始数据(保存在列式数据库或thingsboard平台上)
lng=[{"ts":1655007789001,"value":120.1}, {"ts":1655007759002,"value":120.2}],
lat=[{"ts":1655007789001,"value":36.1}, {"ts":1655007759002,"value":36.2}]
通过org.anyline.thingsboard.util.ThingsBoardClient.getTimeseries()取出列的DataSet结构:
[{"TS":1657707789001, "LNG":120.1, "LAT":36.1},
{"TS":1657707759002, "LNG":120.2, "LAT":36.2}]
DataSet转换成地图轨迹常用的格式:
{
time: [1657707789001, 1657707759002],
path: [
[120.1, 36.1],
[120.2, 36.2],
]
}
取出时间 List<Long> times = set.getLongs("TS");
取出坐标 List<Double[]> points = set.getDoubleArrays("LNG", "LAT");
将所有列中的oldChar替换成newChar
将key列中的oldChar替换成newChar
public DataSet replace(String key, String oldChar, String newChar)
将所有列中的oldChar替换成newChar
public DataSet replace(String oldChar, String newChar)
DataSet清空集合中指定列为空的条目
DataSet set = service.querys("HR_USER");
清空set中DEPT_ID和SORT_ID都为空(包括null和"")的行
public DataSet removeEmptyRow(String... keys)
set.removeEmptyRow("DEPT_ID","SORT_ID");
清除指定列全为空的行,如果不指定keys,则清除所有列都为空(包括null和"")的行
任何一列不为空时,都不会被删除
DataSet实现行转列
DataSet set = service.querys("V_HR_SALARY","YYYY:"+ yyyy, "ORDER BY YM");
DataSet groups = set.pivot("EMPLOYEE_CODE,EMPLOYEE_NM","YM","TOTAL_PRICE");
原数据(240行-20个人12个月)
| 序号 | 工号 | 姓名 | 月份 | 底薪 | 奖金 | 合计 |
| 1 | 1005 | 练霓裳 | 2020-08 | 11000.00 | 200.00 | 10600.00 |
| 2 | 1005 | 练霓裳 | 2020-08 | 11000.00 | 200.00 | 10600.00 |
| 3 | 1005 | 练霓裳 | 2020-08 | 11000.00 | 200.00 | 10600.00 |
| 4 | 1005 | 练霓裳 | 2020-08 | 11000.00 | 200.00 | 10600.00 |
| 5 | 1005 | 练霓裳 | 2020-08 | 11000.00 | 200.00 | 10600.00 |
| 6 | 1005 | 练霓裳 | 2020-08 | 11000.00 | 200.00 | 10600.00 |
| 7 | 1005 | 练霓裳 | 2020-08 | 11000.00 | 200.00 | 10600.00 |
| 8 | 1005 | 练霓裳 | 2020-08 | 11000.00 | 200.00 | 10600.00 |
| 9 | 1005 | 练霓裳 | 2020-08 | 11000.00 | 200.00 | 10600.00 |
| 10 | 1005 | 练霓裳 | 2020-08 | 11000.00 | 200.00 | 10600.00 |
转换结果(20行-20个人,12列-12个月)
| 工号 | 姓名 | 2020-01 | 2020-02 | 2020-03 | 2020-04 | 2020-05 | 2020-06 | 2020-07 | 2020-08 | 2020-09 | 2020-10 | 2020-11 | 2020-12 | 小计(人) |
| 1001 | 风清扬 | 19,400.00 | 22,600.00 | 17,100.00 | 29,000.00 | 15,900.00 | 22,700.00 | 14,900.00 | 17,500.00 | 27,000.00 | 20,100.00 | 28,100.00 | 20,900.00 | 255,200.00 |
| 1007 | 邀月 | 22,300.00 | 21,800.00 | 17,100.00 | 22,800.00 | 20,500.00 | 27,200.00 | 29,300.00 | 25,200.00 | 19,000.00 | 25,600.00 | 28,600.00 | 26,300.00 | 285,700.00 |
| 1011 | 黄药师 | 23,800.00 | 26,900.00 | 16,500.00 | 26,300.00 | 16,400.00 | 29,000.00 | 14,400.00 | 22,400.00 | 21,400.00 | 20,600.00 | 20,100.00 | 28,300.00 | 266,100.00 |
| 1002 | 步惊云 | 15,800.00 | 18,800.00 | 23,000.00 | 13,700.00 | 20,500.00 | 24,600.00 | 12,100.00 | 27,200.00 | 31,300.00 | 13,800.00 | 12,000.00 | 13,500.00 | 226,300.00 |
| 1003 | 李寻欢 | 27,700.00 | 20,000.00 | 14,700.00 | 21,300.00 | 19,000.00 | 24,300.00 | 27,700.00 | 24,900.00 | 16,700.00 | 14,100.00 | 23,100.00 | 17,800.00 | 251,300.00 |
| 1015 | 燕十三 | 15,200.00 | 18,500.00 | 15,900.00 | 13,400.00 | 30,700.00 | 22,000.00 | 28,600.00 | 27,500.00 | 14,000.00 | 14,600.00 | 19,200.00 | 28,600.00 | 248,200.00 |
| 1008 | 王语嫣 | 14,800.00 | 28,400.00 | 27,400.00 | 27,800.00 | 19,000.00 | 24,400.00 | 29,700.00 | 24,500.00 | 19,700.00 | 14,300.00 | 27,700.00 | 23,300.00 | 281,000.00 |
| 1006 | 丁春秋 | 16,000.00 | 33,600.00 | 18,200.00 | 23,100.00 | 24,300.00 | 15,400.00 | 32,800.00 | 21,000.00 | 24,000.00 | 13,200.00 | 27,400.00 | 17,600.00 | 266,600.00 |
| 1013 | 任我行 | 22,600.00 | 30,800.00 | 27,700.00 | 11,700.00 | 33,400.00 | 10,200.00 | 10,800.00 | 18,800.00 | 19,600.00 | 15,600.00 | 21,400.00 | 31,700.00 | 254,300.00 |
| 1019 | 张无忌 | 17,400.00 | 12,900.00 | 13,100.00 | 19,600.00 | 16,300.00 | 30,200.00 | 16,300.00 | 18,600.00 | 15,600.00 | 26,300.00 | 22,100.00 | 26,200.00 | 234,600.00 |
| 1009 | 上官无极 | 30,200.00 | 29,300.00 | 11,500.00 | 29,900.00 | 28,400.00 | 22,700.00 | 30,800.00 | 19,500.00 | 15,100.00 | 31,100.00 | 21,900.00 | 26,200.00 | 296,600.00 |
| 1018 | 慕容复 | 24,700.00 | 18,500.00 | 15,900.00 | 26,800.00 | 14,600.00 | 15,400.00 | 19,800.00 | 9,800.00 | 19,600.00 | 29,600.00 | 14,700.00 | 24,300.00 | 233,700.00 |
| 1017 | 周芷若 | 30,900.00 | 15,700.00 | 13,500.00 | 14,500.00 | 30,100.00 | 27,700.00 | 26,500.00 | 15,400.00 | 29,700.00 | 14,900.00 | 31,500.00 | 19,800.00 | 270,200.00 |
| 1014 | 李莫愁 | 13,800.00 | 14,800.00 | 17,600.00 | 16,100.00 | 24,700.00 | 21,500.00 | 25,000.00 | 16,500.00 | 25,800.00 | 18,800.00 | 24,500.00 | 15,100.00 | 234,200.00 |
| 1004 | 西门吹雪 | 21,300.00 | 28,500.00 | 14,800.00 | 18,200.00 | 21,500.00 | 25,200.00 | 29,200.00 | 27,100.00 | 18,300.00 | 16,900.00 | 28,100.00 | 18,300.00 | 267,400.00 |
| 1016 | 燕南天 | 20,800.00 | 21,700.00 | 13,700.00 | 17,000.00 | 18,300.00 | 11,900.00 | 27,300.00 | 29,400.00 | 11,000.00 | 24,500.00 | 32,800.00 | 28,800.00 | 257,200.00 |
| 1005 | 练霓裳 | 23,000.00 | 19,500.00 | 15,000.00 | 27,200.00 | 33,700.00 | 32,100.00 | 13,600.00 | 17,700.00 | 19,600.00 | 33,000.00 | 24,600.00 | 19,300.00 | 278,300.00 |
| 1012 | 令狐冲 | 13,500.00 | 22,100.00 | 22,900.00 | 20,200.00 | 22,500.00 | 12,600.00 | 33,200.00 | 15,700.00 | 12,300.00 | 24,200.00 | 23,100.00 | 21,000.00 | 243,300.00 |
| 1010 | 欧阳锋 | 18,700.00 | 15,900.00 | 27,400.00 | 26,500.00 | 31,200.00 | 14,500.00 | 31,400.00 | 14,700.00 | 27,200.00 | 27,800.00 | 20,000.00 | 22,000.00 | 277,300.00 |
| 1020 | 小龙女 | 31,000.00 | 18,500.00 | 16,900.00 | 17,900.00 | 14,800.00 | 28,300.00 | 21,400.00 | 26,200.00 | 22,800.00 | 26,800.00 | 26,800.00 | 21,000.00 | 272,400.00 |
| 小计(月) | 422,900.00 | 438,800.00 | 359,900.00 | 423,000.00 | 455,800.00 | 441,900.00 | 474,800.00 | 419,600.00 | 409,700.00 | 425,800.00 | 477,700.00 | 450,000.00 | 5,199,900.00 |
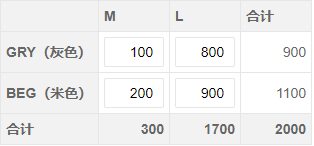
颜色尺寸二维数组交叉表格(DataSet实现垂直水平分组合计)
<table>
<tr class="stat">
<td>尺寸</td>
<c:forEach var="size" items="${sizes}">
<td class="number-cell">${size.NM}</td>
</c:forEach>
<td class="number-cell">合计</td>
</tr>
<c:forEach var="color" items="${colors}">
<tr>
<td class="stat">${color.NM_CN}</td>
<c:forEach var="size" items="${sizes}">
<td class="number-cell">
<al:text data="${all}" var="q" selector="SUIT_ID:${suit.ID},COLOR_ID:${color.ID},SIZE_ID:${size.ID}" property="${col}"></al:text>
${q}
</td>
</c:forEach>
<td class="color-stat stat number-cell" data-suit="${suit.ID}" data-color="${color.ID}">
<span><al:sum data="${all}" var="sumColorQ" selector="SUIT_ID:${suit.ID},COLOR_ID:${color.ID}" property="${col}"></al:sum></span>
${sumColorQ}
</td>
</tr>
</c:forEach>
<tr>
<td class="stat">合计</td>
<c:forEach var="size" items="${sizes}">
<td class="stat size-stat number-cell" data-suit="${suit.ID}" data-size="${size.ID}">
<span><al:sum data="${all}" selector="SUIT_ID:${suit.ID},SIZE_ID:${size.ID}" property="${col}"></al:sum></span>
</td>
</c:forEach>
<td class="stat all-stat number-cell" data-suit="${suit.ID}">
<span><al:sum property="${col}" data="${all}" selector="SUIT_ID:${suit.ID}"></al:sum></span>
</td>
</tr>
</table>
DataSet实现垂直水平分组合计
| | M | L | S | 合计 |
| 纯白 | 20 | 20 | 200 | 240 |
| 天蓝 | 30 | 60 | 120 | 210 |
| 藏青 | 100 | 150 | 500 | 750 |
| 合计 | 150 | 230 | 820 | 1200 |
DataSet按条件过滤
查询DataSet中SORT=1 AND AGE =20 的子集
DataSet result = set.getRows("SORT","1","AGE","20");或set.getRows("SORT:1","AGE:20");
执行后set集合没有改变,会生成一个新集合
DataSet移除每个条目中指定的key
移除DataSet中ID与PASSWORD属性
set.remove("ID","PASSWORD");
DataSet计算总和
计算一列的总和
BigDecimal result = set.sum("PRICE");
计算多列总和DataRow row = set.sums("PRICE","QTY");
DataSet计算平均值
计算一列的平均值
BigDecimal result = set.avg("PRICE");
计算多列平均值DataRow row = set.avgs("PRICE","QTY");
DataSet取最大值最小值
BigDecimalresult = set.maxDecimal("PRICE");
int result = set.maxInt("AGE");
doubleresult = set.maxDouble("RATE");
取金额最大的一个条目
DataRow result = set.max("PRICE");
DataSet提取集合中一列并拼接成String
取集合中所有CODE值并以逗号拼接
String result = set.concat("CODE")
返回001,002,003
以|分隔
String result = set.concat("CODE","|")
返回001|002|003
concatNvl
concatWithoutNull
concatWithoutEmpty
DataSet抽取指定列生成新的DataSet
抽取指定列生成新的DataSet 新的DataSet只包括指定列的值与分页信息,不包含其他附加信息(如来源表)
set.extract("ID","CODE")
新集合中只有ID,CODE两列
DataSet合并两个集合
set1与set2合并生成新的集合
DataSet set = set1.unionAll(set2)
合并不重复的集合,根据ID,CODE判断是否重复
DataSet set = set1.union(set2,"ID","CODE")
查询DataSet中AGE在20到30之间的子集
set.select.between('AGE',20,30)
查询DataSet中CODE in(1,2,3)的子集
set.select.in("CODE",1,2,3)
查询DataSet中PRICE>100的子集
set.select.greater("PRICE",100)
set.select.greaterEqual("PRICE",100)
移除set中指定条件的子集
先通过set.select过滤出符合移除条件的子集,再通过set与子集取差集
DataSet src
DataSet removes = src.select.between("AGE",20,30)
DataSet result = src.difference(removes,"ID");
或
result = src.removeAll(removes);
查询DataSet中NAME以‘张’开头的子集
set.select.like('NAME','张%')
set.select.startWith('NAME','张')
DataSet交集
计算两个DataSet的交集(根据每个条目keys的属性值判断条目是否相同)
set1.intersection(DataSet set2, String ... keys)
如果是多个DataSet可以通过DataSet提供的的静态方法
DataSet.intersection(List<DataSet> sets, String ... keys)
DataSet.select选择器
DataSet.select可以实现类似SQL的查询功能
DataSet.select.setIgnoreCase(boolean bol);
DataSet.select.setIgnoreNull(boolean bol);
DataSet set = new DataSet();
public DataSet set.select.equals(String key, String value);
public DataSet set.select.notEquals(String key, String value);
public DataSet set.select.contains(String key, String value);
public DataSet like(String key, String pattern)
public DataSet notLike(String key, String pattern)
public DataSet startWith(String key, String prefix)
public DataSet endWith(String key, String suffix)
public <T> DataSet in(String key, T ... values)
public<T> DataSet in(String key, Collection<T> values)
public <T> DataSet notIn(String key, T ... values)
public<T> DataSet notIn(String key, Collection<T> values)
public DataSet isNull(String ... keys)
public DataSet isNotNull(String ... keys)
public DataSet isEmpty(String ... keys)
public DataSet isNotEmpty(String ... keys)
public <T> DataSet less(String key, T value)
public <T> DataSet lessEqual(String key, T value)
public <T> DataSet greater(String key, T value)
public <T> DataSet greaterEqual(String key, T value)
public <T> DataSet between(String key, Object min, T max)
DataSet中cut与truncate区别
cut与truncate都是根据条件截取
区别是cut会生成新的DataSet集合不影响DataSet本身
而truncate将直接在源集合上操作,改变源集合的长度
把部门=D的所有用户,分组设置成G
new DataSet().select.equals("DEPT","D").set("GROUP","G");
DataSet实现分组,合并
数据库中有以下数据
| ID | USER_NM | SUBJECT | SCORE |
| 1 | 张三 | 语文 | 90 |
| 2 | 小明 | 语文 | 89 |
| 3 | 李四 | 语文
| 99 |
| 4 | 小明 | 数学 | 87 |
| 5 | 张三 | 数学
| 67 |
| 6 | 李四 | 数字
| 89 |
| 7 | 张三 | 英语 | 87 |
| 8 | 小明 | 英语
| 89 |
| 9 | 李四 | 英语
| 77 |
需要实现以下效果
1.合并单元格
序号
| 姓名
| 学科 | 成绩 |
1
| 张三 | 语文 | 90 |
| 数学 | 67 |
| 英语 | 87 |
2
| 李四
| 语文
| 88 |
数学
| 99 |
英语
| 66 |
3 | 小明 | 语文
| 89 |
数学
| 76 |
英语
| 89 |
不可取的是:先查出所有用户,再遍历用户列表,根据用户查询成绩,需要4次查询
利用DataSet可以实现一次查询
DataSet set = service.query("成绩表");
DataSet groups = set.group("USER_NM");
执行后groups中有3行用户信息,每行用户信息中包括一个成绩集合
实际环境中通常是用户有单独的一个表,并且查询时需要分组,这时需要两次查询实现
1.分页查询用户
DataSet users = service.query("用户表", config(true));
2.根据用户ID区间查询成绩
DataSet scores = service.query("成绩表", "USER_ID:>="+users.getMinId("USER_ID"), "USER_ID:<="+users.getMaxId("USER_ID"));
3.将成绩分配到对应的用户
users.dispatchItem(scores,"ID:USER_ID"); //类似于SQL关联条件中的WHERE USER.ID = SCORE.USER_ID
执行后,每行用户信息中包含一个成绩集合
从人员列表中,查出所有不重复的部门名称
DataSet set = service.query("HR_USER");
set.distinct("DEPARTMENT_NM"); //这里返回的还是人员列表,但一个部门只返回一个.concat("DEPARTMENT_NM"); //这里返回String并以逗号分隔:部门A,部门BList<String> departments = set.getDistinctStrings("DEPARTMENT_NM"); //这里返回一个不重复的部门名称List
DataSet筛选不重复的数据
DataSet result = set.distinct("SORT_CODE","SORT_NM")
DataSet查询
DataSet类似sql的查询
DataSet set = new DataSet();
以DataSet result = set.select.equals("AGE","20")的方式调用
private boolean ignoreNull = true;
public DataSet setIgnoreCase(boolean bol)
public DataSet setIgnoreNull(boolean bol)
public DataSet equals(String key, String value)
public DataSet notEquals(String key, String value)
public DataSet contains(String key, String value)
public DataSet like(String key, String pattern)
public DataSet notLike(String key, String pattern)
public DataSet startWith(String key, String prefix)
public DataSet endWith(String key, String suffix)
public <T> DataSet in(String key, T... values)
public <T> DataSet in(String key, Collection<T> values)
public <T> DataSet notIn(String key, T... values)
public <T> DataSet notIn(String key, Collection<T> values)
public DataSet isNull(String... keys)
public DataSet null(String... keys)
public DataSet isNotNull(String... keys)
public DataSet isEmpty(String... keys)
public DataSet empty(String... keys)
public DataSet isNotEmpty(String... keys)
public DataSet notEmpty(String... keys)
public <T> DataSet less(String key, T value)
public <T> DataSet lessEqual(String key, T value)
public <T> DataSet greater(String key, T value)
public <T> DataSet greaterEqual(String key, T value)
public <T> DataSet between(String key, T min, T max)
EntitySet
与DataSet类似,一般都是由service.querys()返回的查询结果集
DataSet是一个DataRow的集合
EntitySet是一个Entity的集合
数据集操作
DataSet截断
从下标0开始截断到10,方法执行将改变原DataSet长度
DataSet result = set.truncates(0,10)
从begin开始截断到最后一个,如果输入负数则取后n个,如果造成数量不足,则取全部
DataSet result = set.truncates(10);
从begin开始截断到end位置并返回其中第一个DataRow
DataRow result = set.truncate(0,10)
truncates将修改原集合长度,如果不想修改原集合长度可以调用cuts或cut函数,参数与truncates一致





更多建议: