


星火SQL快速指南

星火 - 引言
行业都使用Hadoop广泛地分析他们的数据集。其原因在于Hadoop框架是基于简单的编程模型(MapReduce的),并且它使计算的解决方案,是可扩展的,柔性的,容错和成本效益。在这里,主要关心的是在查询之间的等待时间和等待时间来运行计划的条款处理大型数据集,以保持速度。
火花是由Apache软件基金会推出了加快的Hadoop计算计算软件的过程。
作为对一个共同的信念,Spark是Hadoop的不是一个修改版本 ,不,真的,依赖于Hadoop的,因为它有自己的集群管理。 Hadoop是只是实施星火的方式之一。
星火采用Hadoop的方式有两种-一种是存储和第二个是处理 。由于星火都有自己的集群管理计算,它使用了Hadoop的只有存储的目的。
阿帕奇星火
Apache的Spark是一个闪电般快速的集群计算技术,专为快速计算。它是基于在Hadoop MapReduce和它扩展了MapReduce的模型,以有效地将其用于多种类型的计算,其包括交互式查询和流处理。火花的主要特征是其内存集群计算 ,增加的应用程序的处理速度。
星火旨在涵盖广泛的工作负载,如批量应用,迭代算法,互动查询和流媒体。除了支持所有这些工作负载在各自的系统,它减少了维护单独的工具的管理负担。
阿帕奇星火的演变
Spark是Hadoop的2009年在加州大学伯克利分校的AMPLab由马太·扎哈里亚开发的子项目之一。它是开源的,2010年在BSD许可下。它被捐赠给Apache Software Foundation的2013年,现在的Apache星火已经成为从二月2014年一个顶级Apache项目。
阿帕奇星火特点
阿帕奇星火具有以下特点。
速度 -在磁盘上运行时,星火有助于运行Hadoop集群的应用程序,高达100倍的速度在内存中,快10倍。这通过减少读/写操作的次数,以磁盘是可能的。它存储在内存中的中间处理数据。
支持多国语言 -星火提供了在Java中,斯卡拉,或Python内置的API。因此,你可以写在不同的语言的应用程序。星火配备了80个高层次的经营者进行互动查询。
高级分析 -星火不仅支持'地图'和'减少'。它也支持SQL查询,流数据,机器学习(ML),和图形的算法。
星火内置在Hadoop
下图显示了如何星火可以用Hadoop组件内置三种方式。
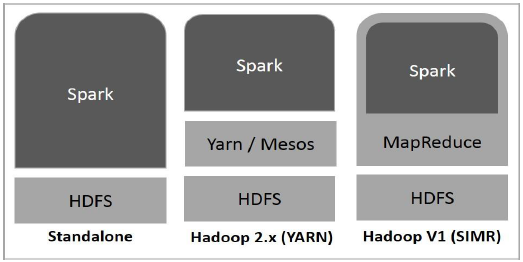
有火花部署三种方式如下面所解释。
单机版-星火独立部署意味着星火上占据HDFS(Hadoop分布式文件系统)和空间顶部的地方分配给HDFS,明确。在这里,星火和MapReduce将并排覆盖在集群中的所有火花的工作。
Hadoop的纱线 - Hadoop的部署纱手段,简单地说,火花对成纱运行而无需任何预先安装或root访问权限。它有助于星火融入的Hadoop生态系统或Hadoop的堆栈。它允许其它组件上叠层的顶部上运行。
在MapReduce的火花(SIMR) -在MapReduce的火花来,除了独立部署开展火花的工作。随着SIMR,用户可以启动Spark和使用它的外壳没有任何管理权限。
星火组件
下图说明了星火的不同组件。
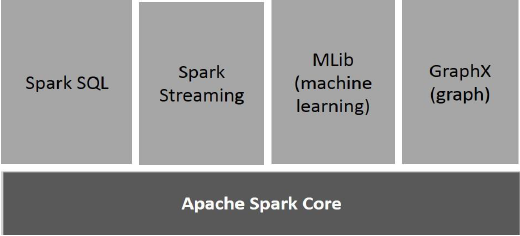
Apache的核心星火
星火Core是,所有其他的功能是建立在这个基础平台火花底层一般执行引擎。它提供了内存计算和外部存储系统引用的数据集。
星火SQL
星火SQL是星火核心之上的组件,它引入了一种名为SchemaRDD一个新的数据抽象,它提供了结构化和半结构化数据的支持。
星火流
星火流利用星火核心的快速调度能力,执行流分析的。它在小批量摄取数据和数据的那些小批量进行RDD(弹性分布式数据集)的转换。
MLlib(机器学习库)
MLlib是一个分布式的机器学习框架以上星火因为分布式基于内存的Spark架构的。据,根据基准,通过对交替最小二乘(ALS)实现的MLlib开发完成的。星火MLlib是九次快的Apache Mahout中的基于磁盘的Hadoop版本(前亨利马乌获得了星火接口)。
GraphX
GraphX是在火花的顶部上的分布式图形处理框架。它提供了用于表达可以通过使用预凝胶抽象API建模用户定义图表图形计算的API。它也提供了这种抽象的优化运行时。
星火 - RDD
弹性分布式数据集
弹性分布式数据集(RDD)是星火的基本数据结构。它是对象的不可变的分布式集合。在RDD每个数据集被划分成逻辑分区,这可能在集群的不同节点上进行计算。 RDDS可以包含任何类型的Python,Java的,或者Scala的对象,包括用户定义的类。
形式上,一个RDD是一个只读分区记录的集合。 RDDS可通过确定性行动上稳定存储或其他RDDS无论是数据被创建。 RDD是可以并行操作的元件的容错集合。
有两种方法可以创建RDDS -在你的驱动程序并行现有的集合,或引用在外部存储系统, 数据集如共享文件系统,HDFS,HBase的,或任何数据源提供Hadoop的输入格式。
火花利用RDD的概念实现更快和有效的MapReduce操作。让我们先讨论如何MapReduce的操作发生,为什么不那么有效。
数据共享是MapReduce的慢
MapReduce的被广泛用于处理和并行产生大型数据集采用,在集群上的分布式算法。它允许用户编写并行计算,使用一组高层次的运营商,而不必担心工作分配和容错能力。
遗憾的是,目前大多数的框架,只有这样,才能重新使用计算(例:二MapReduce任务之间)的数据是将其写入外部稳定的存储系统(例如:HDFS)。虽然这个框架提供了访问群集的计算资源众多抽象,用户还是想要更多。
这两个迭代和交互式应用需要跨并行作业更快速的数据共享。数据共享是缓慢的MapReduce由于复制 , 序列化和磁盘IO。关于存储系统,大部分的Hadoop应用,他们花费的时间的90%以上做HDFS读 - 写操作。
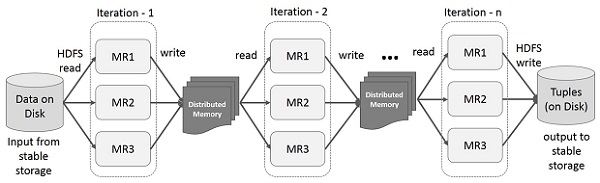
MapReduce的迭代操作
重用多级的应用程序在多个计算中间结果。下图说明了目前的框架是如何工作的,同时做MapReduce的迭代操作。这招致由于数据复制,磁盘I / O和系列化,使系统缓慢实质性开销。

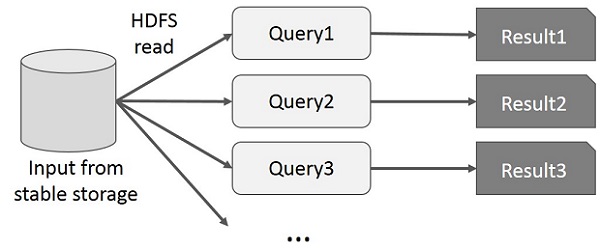
MapReduce的交互式操作
用户运行即席查询对相同的数据子集。每个查询会做的稳定存储,它可以主宰应用程序执行时间的磁盘I / O。
下图说明了目前的框架,同时做交互查询MapReduce的工作方式。
使用星火RDD数据共享
数据共享是缓慢的MapReduce由于复制 , 序列化和磁盘IO。最Hadoop的应用,他们花费的时间的90%以上做HDFS读 - 写操作。
认识到这个问题,研究人员开发了一种称为Apache的星火专门框架。火花的关键思想为R esilientðistributedðatasets(RDD);它支持在内存中处理的计算。这意味着,它存储的存储器状态横跨的作业的对象和对象是那些作业之间共享。在存储器数据共享比网络和磁盘快10到100倍。
现在让我们尝试找出迭代和交互操作如何发生Spark中RDD。
在星火RDD迭代操作
下面给出的图显示星火RDD迭代操作。它将存储在分布式存储器代替稳定存储(磁盘)中间结果,使系统更快。
注 -如果分布式内存(RAM),足以存储中间结果(作业状态),那么将这些结果存储在磁盘上
在星火RDD交互式操作
此图显示星火RDD交互式操作。如果不同的查询在同一组数据的反复运行,该特定数据可被保存在内存中获得更好的执行时间。
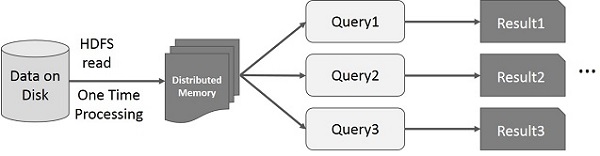
默认情况下,每个变换RDD可在每次运行在其上的动作时间重新计算。然而,你也可能会持续一个RDD在内存中,在这种情况下,星火将保持元件周围的群集上更快地访问,查询它的下一次。此外,还为在磁盘上持续RDDS支持,或跨多个节点的复制。
星火 - 安装
Spark是Hadoop的子项目。因此,最好是火花安装到基于Linux系统。下列步骤显示了如何安装Apache的火花。
步骤1:验证安装的Java
安装Java是在安装星火强制性的事情之一。试试下面的命令来验证Java版本。
$java -version
如果Java已经,安装在系统上,你能看到以下响应 -
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果你没有在系统上安装了Java,那么在进行下一步之前,安装Java。
第二步:验证安装斯卡拉
你应该Scala语言来实现的火花。因此,让我们用下面的命令验证斯卡拉安装。
$scala -version
如果Scala是已经安装在系统中,你能看到以下响应 -
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
如果你没有在系统上安装斯卡拉,然后进行斯卡拉安装下一个步骤。
第三步:下载斯卡拉
通过访问下载最新版本的斯卡拉下面的链接下载斯卡拉 。在本教程中,我们将使用Scala-2.11.6版本。下载后,您会发现在下载文件夹斯卡拉tar文件。
第四步:安装斯卡拉
按照安装斯卡拉下面给出的步骤。
提取斯卡拉tar文件
用于提取斯卡拉tar文件键入以下命令。
$ tar xvf scala-2.11.6.tgz
斯卡拉移动软件文件
使用以下命令为斯卡拉软件文件,移动到相应目录(在/ usr /本地/斯卡拉)。
$ su – Password: # cd /home/Hadoop/Downloads/ # mv scala-2.11.6 /usr/local/scala # exit
斯卡拉设置PATH
为斯卡拉设置PATH使用下面的命令。
$ export PATH = $PATH:/usr/local/scala/bin
验证安装斯卡拉
安装完毕后,最好是进行验证。验证斯卡拉安装使用下面的命令。
$scala -version
如果Scala是已经安装在系统中,你能看到以下响应 -
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
第五步:下载Apache的星火
通过访问以下链接下载最新版本的星火下载星火 。在本教程中,我们使用的是火花1.3.1彬hadoop2.6版本。下载后,你会发现在下载文件夹星火tar文件。
第六步:安装星火
按照安装星火下面给出的步骤。
星火提取焦油
提取火花tar文件下面的命令。
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgz
移动星火软件文件
对于Spark软件文件移动到相应目录(在/ usr /本地/火花)以下命令。
$ su – Password: # cd /home/Hadoop/Downloads/ # mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark # exit
设置为星火环境
以下行添加到〜/.bashrc文件。这意味着添加的位置,那里的火花软件文件的位置到PATH变量。
export PATH = $PATH:/usr/local/spark/bin
对采购的〜/ .bashrc文件使用以下命令。
$ source ~/.bashrc
第七步:验证安装星火
写打开外壳星火以下命令。
$spark-shell
如果火花塞安装成功,那么你会发现下面的输出。
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>
星火SQL - 引言
星火推出名为星火SQL结构化数据处理的编程模块。它提供了一个编程抽象称为数据框中,可以作为分布式SQL查询引擎作用。
星火SQL的特点
以下是星火SQL的功能 -
集成 -无缝星火计划混合使用SQL查询。星火SQL可以让你查询的结构化数据为星火分布式数据集(RDD),使用Python,Scala和Java集成的API。这种紧密集成可以很容易地同时运行复杂的分析算法SQL查询。
统一的数据访问 -从各种来源加载和查询数据。架构RDDS提供与结构化数据,包括Apache蜂巢桌,实木复合地板的文件和文件JSON工作效率的单一接口。
蜂巢兼容性 -在现有的仓库运行未经修改的蜂巢查询。星火SQL重用蜂房前端和MetaStore,让您与现有的数据蜂房,查询和UDF完全兼容。只要沿着蜂巢安装。
标准连接 -连接通过JDBC或ODBC。星火SQL包括与行业标准的JDBC和ODBC连接的服务器模式。
可扩展性 -使用相同的引擎,交互和长查询。星火SQL取RDD模式,支持中端查询容错的优势,让它扩展到大型工作过。不要担心使用不同引擎的历史数据。
星火SQL架构
下图说明了星火SQL的架构 -
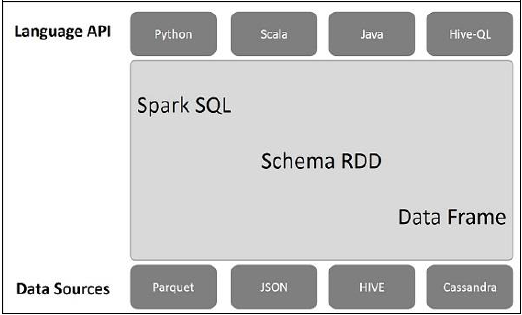
该架构包含三个层次,即语言的API,架构RDD,和数据源。
语言API - Spark是用不同的语言和SQL星火兼容。同时,这也是这些书写的API(蟒蛇,斯卡拉,JAVA,HiveQL)的支持。
架构RDD -星火核心设计了名为RDD特殊的数据结构。一般地,火花SQL工作在模式,表和记录。因此,我们可以使用架构作为RDD临时表。我们可以把这种架构作为RDD数据帧。
数据源 -一般的数据源火花核心是一个文本文件,阿夫罗文件等,但是,对于火花SQL数据源是不同的。这些都是平面文件,JSON文档,HIVE表和卡桑德拉数据库。
我们将讨论更多关于这些在后面的章节。
星火SQL - DataFrames
一个数据帧是数据,这些数据被组织到一个名为列的分布式的集合。从概念上讲,它是等效于具有良好优化技术关系表。
一个数据框可以从不同的来源,如蜂房的表,结构化的数据文件,外部数据库,或现有RDDS数组构造。这个API被设计为 在Python - [R编程和大熊猫取灵感来自于现代数据框大数据和数据的科学应用。
数据框的特点
下面是一组数据帧的一些特征 -
能够处理单个节点群集到大集群以KB为单位的大小来拍字节的数据。
支持不同的数据格式(Avro的,CSV,弹性搜索和卡桑德拉)和存储系统(HDFS,HIVE表,MySQL等)。
通过星火SQL优化催化剂(树转换框架)技术优化和代码生成状态。
可通过星火核与所有大数据工具和框架轻松集成。
提供API的Python,Java中,斯卡拉和R编程。
SQLContext
SQLContext是一类,并用于初始化火花的SQL的功能。 SparkContext类对象(SC)所需的初始化SQLContext类对象。
下面的命令用于通过火花壳初始化SparkContext。
$ spark-shell
默认情况下,SparkContext对象与名称SC火花-壳启动时初始化。
使用下面的命令来创建SQLContext。
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)
例
让我们在一个名为employee.json一个JSON文件考虑员工记录的例子。使用下面的命令来创建一个数据帧(DF)和读取命名employee.json具有下列内容的JSON文件。
employee.json -将这个文件在当前斯卡拉>指针所在的目录。
{
{"id" : "1201", "name" : "satish", "age" : "25"}
{"id" : "1202", "name" : "krishna", "age" : "28"}
{"id" : "1203", "name" : "amith", "age" : "39"}
{"id" : "1204", "name" : "javed", "age" : "23"}
{"id" : "1205", "name" : "prudvi", "age" : "23"}
}
数据框操作
数据框提供了结构化数据处理领域特定语言。在这里,我们包括使用DataFrames结构化数据处理的一些基本例子。
按照下面给出的数据框进行操作的步骤 -
阅读JSON文件
首先,我们要读的JSON文件。在此基础上,产生一个命名为(DFS)数据帧。
使用下面的命令来读取名为employee.json的JSON文件。的数据被示出为与字段的表 - 编号,姓名和年龄。
scala> val dfs = sqlContext.read.json("employee.json")
输出 -字段名得自employee.json自动拍摄照片。
dfs: org.apache.spark.sql.DataFrame = [age: string, id: string, name: string]
显示数据
如果你想看到的数据框的数据,然后使用以下命令。
scala> dfs.show()
输出 -你可以看到以表格格式员工数据。
<console>:22, took 0.052610 s +----+------+--------+ |age | id | name | +----+------+--------+ | 25 | 1201 | satish | | 28 | 1202 | krishna| | 39 | 1203 | amith | | 23 | 1204 | javed | | 23 | 1205 | prudvi | +----+------+--------+
使用方法printSchema
如果你想看到的数据框的结构(架构),然后使用下面的命令。
scala> dfs.printSchema()
产量
root |-- age: string (nullable = true) |-- id: string (nullable = true) |-- name: string (nullable = true)
使用选择方法
使用下面的命令从数据框的三列中取的名字 -column。
scala> dfs.select("name").show()
输出 -你可以看到名字列的值。
<console>:22, took 0.044023 s +--------+ | name | +--------+ | satish | | krishna| | amith | | javed | | prudvi | +--------+
使用过滤器时代
寻找那些年龄超过23(年龄> 23)越大,员工使用下面的命令。
scala> dfs.filter(dfs("age") > 23).show()
产量
<console>:22, took 0.078670 s +----+------+--------+ |age | id | name | +----+------+--------+ | 25 | 1201 | satish | | 28 | 1202 | krishna| | 39 | 1203 | amith | +----+------+--------+
使用方法GROUPBY
用于计算员工谁是同年龄的号码使用下列命令。
scala> dfs.groupBy("age").count().show()
输出 -这两个雇员有23岁。
<console>:22, took 5.196091 s +----+-----+ |age |count| +----+-----+ | 23 | 2 | | 25 | 1 | | 28 | 1 | | 39 | 1 | +----+-----+
运行SQL查询编程
一个SQLContext使应用程序能够运行编程在运行SQL函数的SQL查询并返回结果作为一个数据帧。
通常,在后台,SparkSQL支持用于转换现有RDDS成DataFrames两种不同的方法 -
| 不老 | 方法和说明 |
|---|---|
| 1 | 推断使用反射架构 这种方法使用反射来生成包含特定类型的对象的RDD的模式。 |
| 2 | 编程指定模式 创建数据帧的第二种方法是通过编程接口,使您可以构建一个架构,然后将其应用到现有的RDD。 |
星火SQL - 数据来源
一个数据帧的接口允许不同的数据源对SQL星火工作。它是一个临时表,并且可以作为一个正常的RDD操作。注册一个数据帧作为一个表,您可以在其数据上运行SQL查询。
在本章中,我们将介绍使用不同的数据源星火加载和保存数据的一般方法。此后,我们将详细讨论可用于内置数据源的特定选项。
有在SparkSQL可用不同类型的数据源,其中的一些列举如下 -
| 不老 | 数据源 |
|---|---|
| 1 | JSON数据集 星火SQL可以自动捕捉一个JSON数据集的架构并加载它作为一个数据帧。 |
| 2 | 蜂巢表 蜂巢捆绑了星火库HiveContext,从SQLContext继承。 |
| 3 | 实木复合地板的文件 实木复合地板是一个柱状的格式,许多数据处理系统的支持。 |



更多建议: