
在这个信息爆炸的时代,数据就是黄金。对于大语言模型(LLM)来说,高质量的训练数据更是无价之宝。然而,传统的网络爬虫在面对复杂多变的现代网页时,常常力不从心。这时,一款革命性的工具——FireCrawl横空出世,让数据采集变得如此简单,堪称是给大模型喂食的神器!

FireCrawl不只是普通的网络爬虫,它是为大语言模型量身打造的数据采集利器。它能够轻松应对JavaScript动态生成的内容,无需站点地图就能深入网站的每个角落,将复杂的网页结构转化为LLM可以直接理解的格式。这简直就是给大模型准备了一份随时可以享用的美味大餐!
还在为复杂的爬虫代码头疼吗?FireCrawl提供了超级友好的API和在线平台,只需要输入目标网址,点击一个按钮,就能开始数据的狂欢。它就像是给你配了一个24小时不知疲倦的助手,不停地为你收集互联网上的精华内容。
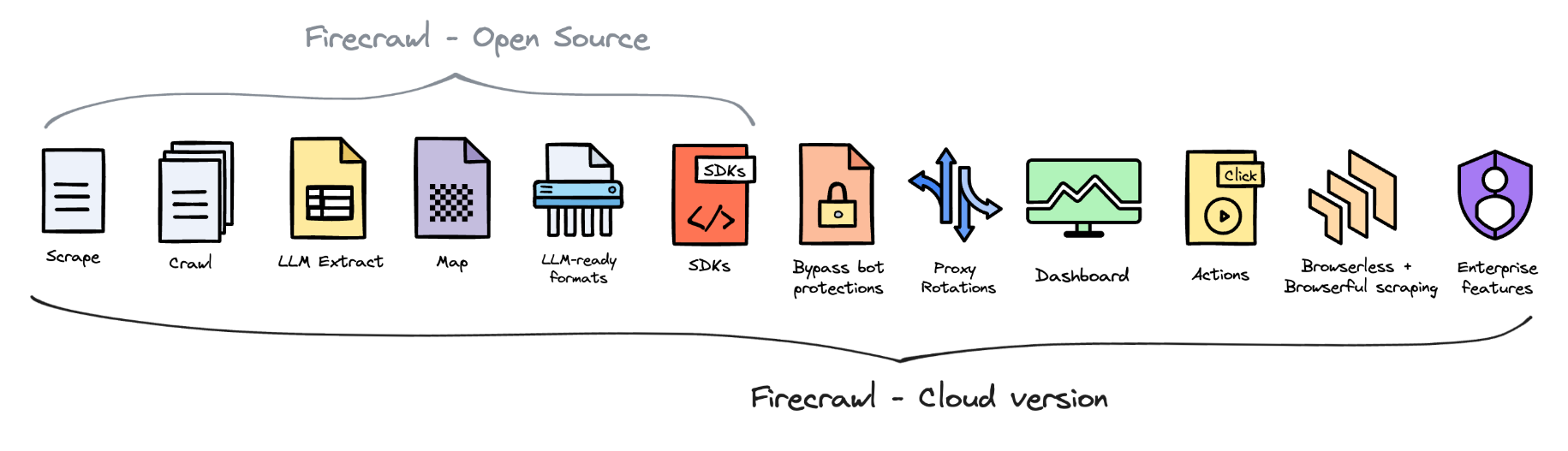
FireCrawl不只是简单地复制粘贴网页内容。它会智能地提取主要内容,过滤掉广告和无关信息,甚至可以将内容转换成Markdown格式。这就像是给大模型准备了一份精心烹制的大餐,每一口都是营养满分的知识精华。
有了FireCrawl,你可以轻松构建自己的知识库,为检索增强生成(RAG)系统提供源源不断的新鲜数据。想象一下,你的AI助手能够实时获取最新的网络信息,回答的问题总是紧跟时代脉搏,这将会给用户带来多么惊艳的体验啊!
对于那些想要打造下一代AI应用的开发者来说,FireCrawl简直就是及时雨。它提供了丰富的SDK支持,兼容多种编程语言,可以无缝集成到你的项目中。无论你是要训练专属的语言模型,还是构建实时更新的知识图谱,FireCrawl都能成为你得力的助手。
在AI飞速发展的今天,谁掌握了高质量的数据,谁就掌握了未来。FireCrawl不仅仅是一个工具,它代表了一种新的数据采集理念。它告诉我们,在人工智能时代,数据的价值不仅在于数量,更在于质量和即时性。
有了FireCrawl,我们可以期待看到更多智能、实时、个性化的AI应用涌现。也许在不久的将来,每个人都能够轻松打造自己的专属AI助手,而这一切的基础,都将建立在FireCrawl这样的革命性工具之上。
朋友们,未来已经来临,而FireCrawl正在为我们打开通向这个未来的大门。让我们一起拥抱这个数据驱动的新时代,用FireCrawl武装自己,在AI的海洋中乘风破浪,创造无限可能!









