
 免费 AI IDE
免费 AI IDE
在python的数据分析中,数据分析前需要对数据进行读取,数据分析结束后要进行数据存储,可以说数据读取与存储是数据分析最必不可少的步骤,那么python的数据分析中怎么进行数据读取与存储呢?接下来的这篇文章告诉你。
一、图示
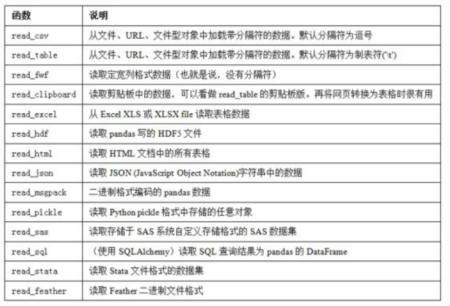

二、csv文件
1.读取csv文件read_csv(file_path or buf,usecols,encoding):file_path:文件路径,usecols:指定读取的列名,encoding:编码
data = pd.read_csv('d:/test_data/food_rank.csv',encoding='utf8')
data.head()
name num
0 酥油茶 219.0
1 青稞酒 95.0
2 酸奶 62.0
3 糌粑 16.0
4 琵琶肉 2.0
#指定读取的列名
data = pd.read_csv('d:/test_data/food_rank.csv',usecols=['name'])
data.head()
name
0 酥油茶
1 青稞酒
2 酸奶
3 糌粑
4 琵琶肉
#如果文件路径有中文,则需要知道参数engine='python'
data = pd.read_csv('d:/数据/food_rank.csv',engine='python',encoding='utf8')
data.head()
name num
0 酥油茶 219.0
1 青稞酒 95.0
2 酸奶 62.0
3 糌粑 16.0
4 琵琶肉 2.0
#建议文件路径和文件名,不要出现中文
2.写入csv文件
DataFrame:to_csv(file_path or buf,sep,columns,header,index,na_rep,mode):file_path:保存文件路径,默认None,sep:分隔符,默认',' ,columns:是否保留某列数据,默认None,header:是否保留列名,默认True,index:是否保留行索引,默认True,na_rep:指定字符串来代替空值,默认是空字符,mode:默认'w',追加'a'
**Series**:`Series.to_csv`(_path=None_,_index=True_,_sep='_,_'_,_na\_rep=''_,_header=False_,_mode='w'_,_encoding=None_)三、数据库交互
pandas
sqlalchemy
pymysql
# 导入必要模块
import pandas as pd
from sqlalchemy import create_engine
#初始化数据库连接
#用户名root 密码 端口 3306 数据库 db2
engine = create_engine('mysql+pymysql://root:@localhost:3306/db2')
#查询语句
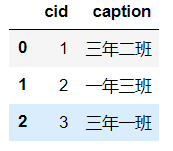
sql = '''
select * from class;
'''
#两个参数 sql语句 数据库连接
df = pd.read_sql(sql,engine)
df
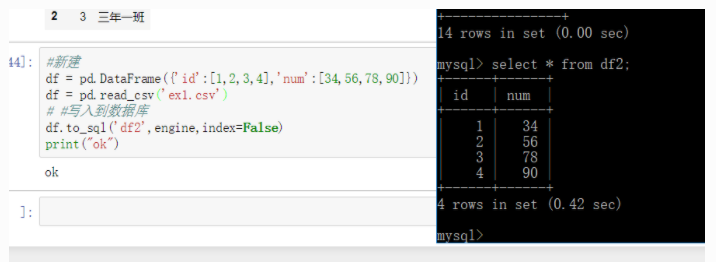
#新建
df = pd.DataFrame({'id':[1,2,3,4],'num':[34,56,78,90]})
df = pd.read_csv('ex1.csv')
# #写入到数据库
df.to_sql('df2',engine,index=False)
print("ok")进入数据库查看 :
到此这篇关于Python数据分析入门之数据读取与存储的文章就介绍到这了,更多python学习内容请搜索W3Cschool以前的文章或继续浏览下面的相关文章。



