

简介
Apache Beam 2.23.0现已发布。Apache Beam 是 Google 在 2016 年 2 月份贡献给 Apache基金会的项目,主要目标是统一批处理和流处理的编程范式,为无限、乱序、web-scale 的数据集处理提供简单灵活,功能丰富以及表达能力十分强大的 SDK。Apache Beam项目重点在于数据处理的编程范式和接口定义,并不涉及具体执行引擎的实现,Apache Beam 希望基于 Beam 开发的数据处理程序可以执行在任意的分布式计算引擎上。
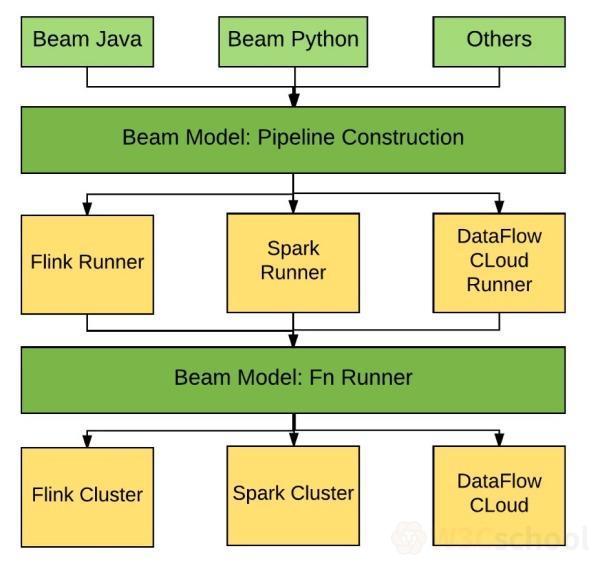
主要更新内容:
Highlights
Twister2 Runner(BEAM-7304)。
Python 3.8支持(BEAM-8494)。
I/Os
- 添加了对
Snowflake reading的支持(Java)(BEAM-9722)。
- 增加了对写入
Splunk的支持(Java)(BEAM-8596)。
- 添加了对
assume role的支持(Java)(BEAM-10335)。
- 已添加一个新的可从
BigQuery读取的 transform:apache_beam.io.gcp.bigquery.ReadFromBigQuery。此transform是实验性的。它通过将数据导出到Avro文件并读取这些文件来从BigQuery读取数据。它还支持通过导出到JSON文件来读取数据。与时间和日期相关的字段在行为上有很小的差异。
- 为
SnowflakeIO.write添加dispositions(BEAM-10343)
New Features/Improvements
更新 Snowflake JDBC 依赖关系,并将 application=beam 添加到 connection URL(BEAM-10383)。
Breaking Changes
- 在反序列化 JSON(Java)时,
RowJson.RowJsonDeserializer、JsonToRow和PubsubJsonTableProvider现在默认接受“implicit nulls”。以前的 null 只能用 explicit null 值表示,例如{"foo": "bar", "baz": null},而像{"foo": "bar"}这样的implicit null值则会引发异常。现在,两个 JSON 字符串默认都会产生相同的结果。可以使用用RowJson.RowJsonDeserializer#withNullBehavior来覆盖此行为。
- 修复 Python 中
GroupIntoBatches实验转换中的一个错误,该错误实际上是按键对批次进行分组的。这将更改此转换的输出类型(BEAM-6696)。
Deprecations
- 删除 Gearpump runner。(BEAM-9999)
- 删除 Apex 运行程序。(BEAM-9999)
- RedisIO.readAll() 已被弃用,将在 2 个版本中删除,用户必须使用 RedisIO.readKeyPatterns() 作为替代(BEAM-9747)。



