

数据标准化操作是指将数据按比例缩放,使之落入一个小的特定区间。这样的操作在机器学习中是比较常用的。在python中我们可以使用pandas模块来实现数据标准化,那么怎么使用pandas模块实现数据标准化呢?接下来这篇文章告诉你。
如下所示:
| 3σ 原则 | (u-3*σ ,u+3*σ ) |
| 离差标准化 | (x-min)/(max-min) |
| 标准差标准化 | (x-u)/σ |
| 小数定标标准化 |
x/10**k k=np.ceil(log10(max(|x|))) |
1.3σ原则
u 均值
σ 标准差
正太分布的数据基本都分布在(u-3σ,u+3σ)范围内
其他的数据
import pandas as pd
import numpy as np
def three_sigma(se):
"""
自实现3σ原则,进行数据过滤
:param se:传进来的series结构数据
:return:去除异常值之后的series数据
"""
bool_id=((se.mean()-3*se.std())<se) & (se<(se.mean()+3*se.std()))
print(bool_id)
return se[bool_id]
#加载数据
detail=pd.read_excel('./meal_order_detail.xlsx')
#进行异常值处理
res=three_sigma(detail['amounts'])
print(detail.shape)
print(res.shape)2.离差标准化
(x-min)/(max-min)import pandas as pd
import numpy as np
def minmax_sca(data):
"""
离差标准化
param data:传入的数据
return:标准化之后的数据
"""
new_data=(data-data.min())/(data.max()-data.min())
return new_data
#加载数据
detail=pd.read_excel('./meal_order_detail.xlsx')
res=minmax_sca(detail[['amounts','counts']])
print(res)
data=res
bool_id=data.loc[:,'count']==1
print(data.loc[bool_id],'counts')3.标准差标准化
(x-u)/σ
异常值对标准差标准化的影响不大
转化之后的数据--->均值0 标准差1
import pandas as pd
import numpy as np
def stand_sca(data):
"""
标准差标准化
:param data:传入的数据
:return:标准化之后的数据
"""
new_data=(data-data.mean())/data.std()
return new_data
#加载数据
detail=pd.read_excel('./meal_order_detail.xlsx')
res=stand_sca(detail[['amounts','counts']])
print(res)
print('res的均值:',res.mean())
print('res的标准差:',res.std())4.小数定标标准化
x/(10^k)
k=math.ceil(log10(max(|x|)))
以10为底,x的绝对值的最大值的对数 最后进行向上取整
import pandas as pd
import numpy as np
def deci_sca(data):
"""
自实现小数定标标准化
:param data: 传入的数据
:return: 标准化之后的数据
"""
new_data=data/(10**(np.ceil(np.log10(data.abs().max()))))
return new_data
#加载数据
detail = pd.read_excel('./meal_order_detail.xlsx')
res = deci_sca(detail[['amounts', 'counts']])
print(res)补充:pandas数据处理基础之标准化与标签数值化
fit(): Method calculates the parameters μ and σ and saves them as internal objects.
解释:简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。
transform(): Method using these calculated parameters apply the transformation to a particular dataset.
解释:在fit的基础上,进行标准化,降维,归一化等操作(看具体用的是哪个工具,如PCA,StandardScaler等)。
fit_transform(): joins the fit() and transform() method for transformation of dataset.
解释:fit_transform是fit和transform的组合,既包括了训练又包含了转换。 transform()和fit_transform()二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等)
fit_transform(trainData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。
Note:
必须先用fit_transform(trainData),之后再transform(testData)
如果直接transform(testData),程序会报错
如果fit_transfrom(trainData)后,使用fit_transform(testData)而不transform(testData),虽然也能归一化,但是两个结果不是在同一个“标准”下的,具有明显差异。(一定要避免这种情况)
注意:StandardScaler().fit_transform(x,fit_params),fit_params决定标准化的标签数据,就是每个标准化的标杆数据,此参数不同,则每次标准化的过程则不同。
from sklearn import preprocessing
# 获取数据
cols = ['OverallQual','GrLivArea', 'GarageCars','TotalBsmtSF', 'FullBath', 'TotRmsAbvGrd', 'YearBuilt'] ##选取列
x = data_train[cols].values
y = data_train['SalePrice'].values
x_scaled = preprocessing.StandardScaler().fit_transform(x) ##进行归一化
y_scaled = preprocessing.StandardScaler().fit_transform(y.reshape(-1,1))##先将y转换成一列,再进行归一
还有以下形式,和上面的标准化原理一致,都是先fit,再transform。
由ss决定标准化进程的独特性
# 先将数据标准化
from sklearn.preprocessing import StandardScaler
ss = StandardScaler() ##
#用测试集训练并标准化
ss.fit(missing_age_X_train)##首先fit
missing_age_X_train = ss.transform(missing_age_X_train) #进行transform
missing_age_X_test = ss.transform(missing_age_X_test)标签数值化
1.当某列数据不是数值型数据时,将难以标准化,此时要将数据转化成数据型形式。
数据处理前数据显示:
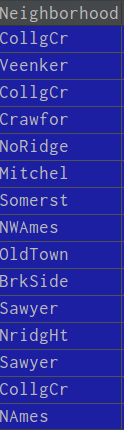
经过标签化数据处理
from sklearn import preprocessing
f_names = ['CentralAir', 'Neighborhood'] ##需要处理的数据标签
for x in f_names:
label = preprocessing.LabelEncoder()
data_train[x] = label.fit_transform(data_train[x]) ##数据标准化处理之后变成:
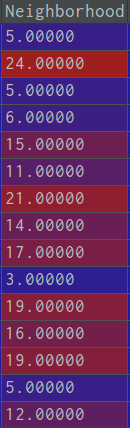
2.当某列有对应的标签值时,即某个量对应相应确定的标签时,例如oldtown就对应1,sawyer就对应2,分类的str转换为序列类这时使用如下:
数据处理之前
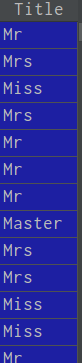
利用转换:
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}#将标签对应数值
train_df['Title'] = train_df['Title'].map(title_mapping)#处理数据
train_df['Title'] = train_df['Title'].fillna(0)##将其余标签填充为0值处理过后:
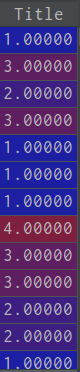
3.多个数据标签需要分列采用one_hot形式时,处理之前

处理之后
train_test.loc[train_test["Age"].isnull() ,"age_nan"] = 1 ##将标签转换成1
train_test.loc[train_test["Age"].notnull() ,"age_nan"] = 0##将此标签成为0
train_test = pd.get_dummies(train_test,columns=['age_nan']) ##columns决定哪几行分列处理,prefix参数是每列前缀
one_hot 形式转变成功。
以上就是怎么使用pandas模块实现数据标准化的全部内容了,希望能给大家一个参考,也希望大家多多支持W3Cschool。



