

相信很多学习C语言、Java等编程语言的小伙伴们在掌握了基础语法后就了解到了数据结构与算法,这两个学科熬秃了多少程序员的头。数据结构和算法的关系是依赖的,实现算法需要一定的数据结构,数据结构有很多种类,其中最简单的一种就是线性表,而线性表中又分为顺序表和链式表(简称链表),我们就来介绍一下线性表的这两种表。
基础数据类型
我们知道,每一门语言都有一些基础的数据类型,比如int,float,char,这些数据类型就像一个一个的点。但是我们在实际使用的时候会把一些有关联的点组合起来使用,这就是有结构的数据(比如将一个一个的数据存放在一起,这就是一个集合(枚举类型))。
线性表
数据结构不仅描述了数据的格式,还描述了数据与数据间的关系,最常见的就是数据与数据之间一一联系,前一个数据和后一个数据相连,这种数据结构最后会像线一样连成一串,这种数据结构也因此得名为线性表。
线性表的实现有两种形式,这两种实现方式的不同主要是内存造成的:
顺序表
实现线性表的最简单的方式,就是在一片连续的内存中按照顺序填充数据,这样每个数据都会像排队一样在内存空间里有一定的位置。要访问数据的前一个数据,只要在内存中相应偏移一定的量(通常是一个数据的长度),就能访问到相应的数据,访问后一个数据也可以使用相同的方式。
实际上在看到连续的内存这个字眼,小伙伴们应该马上就想到了吧?没错,就是数组(在python中没有数组,但有队列和元组,在此处对应的是元组,下文会有所介绍)
| null | arr0=W | arr1=3 | arr2=C | arr3=S | arr4=C | arr5=H | arr6=o | arr7=o | arr8=l |
| null | null | null | null | null | null | null | null | null | null |
如上所示,这就是一个典型的顺序表。
顺序表的问题
前文中我们提到,创建顺序表需要开辟一块固定的空间,通常这个空间开辟后就无法修改其容量,也就是所这个顺序表初始化的时候只能存放10个数据,就不能存放超过十个数据。这样的使用会存在这样的问题:我怎么知道我需要多大的空间,换言之,在不知道需要多大空间的时候,使用顺序表就要根据经验来判断了,如果预先开辟过大的空间,就会有空间浪费的问题。另外,顺序表的数据操作也有一定的资源浪费,修改数据上逻辑是正常的,我只要到固定的位置改动数据即可,删除和添加最后一个数据也是正常的,还是到最后的位置处理数据即可,那么我要在顺序表中间或者开头插入一个数据呢?这个时候我就要在要插入的位置开始,将所有的数据后移一位,才能将新数据填充进去,删除也有同样的情况,要将要删除的
此外还有另一个问题:如果我本身没有这么多空间呢?内存的使用并不是有规律的,开辟一块固定宽度的空间很多时候只是一种奢求,如何在支零破碎的内存中利用好每个空隙,这就是接下来的主角——链式表的优势了。
链式表
与顺序表不同,顺序表是将一堆数据捆在一起,使用物理相邻的方式来确定他们的关系。而链式表这是数据与数据之间各自在其内存空间,不过数据中保存着访问下一个(或者上一个)数据的方法。如何通俗的理解这个方法呢?假如一群朋友去看电影,但是没有办法买到连坐的位置,想要知道某个人的位置,你可以问旁边的你的朋友,因为你知道你旁边的你的朋友在哪,而你的朋友又可以问你的另一个朋友,知道找到那个朋友。如下所示:
| arr1 =W
下一个目标是 第三格 |
null | arr2 =3
下一个目标是 第五格 |
null | arr3 =C
下一个目标是 第六格 |
arr4=/0
这里是链表尾部 |
null |
在C语言中使用指针来保存下一个(或上一个)数据的数据地址,在其他语言中使用引用来保存下一个(或者上一个)的数据(因为是引用,所以实际上也是保存了一个数据地址),如下所示:
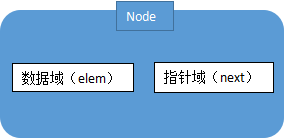
一个node就是一个数据,也就是一个数据节点,每个节点由数据域和指针域构成,数据域用来存放数据,而指针域用来指定下一个目标节点。
由于链表的这种特性,要在中间插入一个数据,只需要新建一个数据节点,然后将前一个数据的指针域指向这个新数据,然后将这个新数据指向后一个指针域即可。删除也很简单,我们只需要将前一个数据的指针域指向下一个数据,然后删除这个数据即可(在c语言中线性表需要自行实现,或者使用相应的库,而在python中列表具有相应的功能,但列表并不只是单纯的链式表,你可以看做他是链式表的升级版或者超集)。
要想知道一个链表有多少个数据节点,只有将所有的数据遍历过才能知道,当然,你可以选择用一个数据节点来保存这个链表的长度,但是你需要访问最后一个节点,假如这个链表的长度为十万个,那么就需要执行十万次数据读取才能得到这个节点的数据,而顺序表只需要一次(他可以直接通过内存偏移得到相应的数据)
链表的C语言实现:单链表
#include <stdio.h>
#include <stdlib.h>
typedef struct Link{
int elem;
struct Link *next;
}link;
link * initLink();
//链表插入的函数,p是链表,elem是插入的结点的数据域,add是插入的位置
link * insertElem(link * p,int elem,int add);
//删除结点的函数,p代表操作链表,add代表删除节点的位置
link * delElem(link * p,int add);
//查找结点的函数,elem为目标结点的数据域的值
int selectElem(link * p,int elem);
//更新结点的函数,newElem为新的数据域的值
link *amendElem(link * p,int add,int newElem);
void display(link *p);
int main() {
//初始化链表(1,2,3,4)
printf("初始化链表为:\n");
link *p=initLink();
display(p);
printf("在第4的位置插入元素5:\n");
p=insertElem(p, 5, 4);
display(p);
printf("删除元素3:\n");
p=delElem(p, 3);
display(p);
printf("查找元素2的位置为:\n");
int address=selectElem(p, 2);
if (address==-1) {
printf("没有该元素");
}else{
printf("元素2的位置为:%d\n",address);
}
printf("更改第3的位置的数据为7:\n");
p=amendElem(p, 3, 7);
display(p);
return 0;
}
link * initLink(){
link * p=(link*)malloc(sizeof(link));//创建一个头结点
link * temp=p;//声明一个指针指向头结点,用于遍历链表
//生成链表
for (int i=1; i<5; i++) {
link *a=(link*)malloc(sizeof(link));
a->elem=i;
a->next=NULL;
temp->next=a;
temp=temp->next;
}
return p;
}
link * insertElem(link * p,int elem,int add){
link * temp=p;//创建临时结点temp
//首先找到要插入位置的上一个结点
for (int i=1; i<add; i++) {
if (temp==NULL) {
printf("插入位置无效\n");
return p;
}
temp=temp->next;
}
//创建插入结点c
link * c=(link*)malloc(sizeof(link));
c->elem=elem;
//向链表中插入结点
c->next=temp->next;
temp->next=c;
return p;
}
link * delElem(link * p,int add){
link * temp=p;
//遍历到被删除结点的上一个结点
for (int i=1; i<add; i++) {
temp=temp->next;
}
link * del=temp->next;//单独设置一个指针指向被删除结点,以防丢失
temp->next=temp->next->next;//删除某个结点的方法就是更改前一个结点的指针域
free(del);//手动释放该结点,防止内存泄漏
return p;
}
int selectElem(link * p,int elem){
link * t=p;
int i=1;
while (t->next) {
t=t->next;
if (t->elem==elem) {
return i;
}
i++;
}
return -1;
}
link *amendElem(link * p,int add,int newElem){
link * temp=p;
temp=temp->next;//tamp指向首元结点
//temp指向被删除结点
for (int i=1; i<add; i++) {
temp=temp->next;
}
temp->elem=newElem;
return p;
}
void display(link *p){
link* temp=p;//将temp指针重新指向头结点
//只要temp指针指向的结点的next不是Null,就执行输出语句。
while (temp->next) {
temp=temp->next;
printf("%d",temp->elem);
}
printf("\n");
}回到上文的问题
为什么在python中顺序表对应的是元组而不是列表?原因很简单,python的列表是可以从中间插入数据的,而这是链式表的特性,元组不能实现这个功能。
小结:顺序表和链式表的优缺点比较
| 顺序表 | 链式表 | |
| 内存使用 | 连续的一块空间,数据相邻,通过物理相邻的方式实现数据之间的联系 。
因此不能动态调整长度 (内存使用率较低) |
每个数据节点不一定相邻,通过指针的方式实现数据之间的联系
因此可以调整动态长度 |
| 删除 | 可以删除最后一个数据,删除其他位置的数据的时候需要将相应的数据前移
(删除成本高) |
数据可以随意删除,只需要将前一个节点的指针指向后一个节点 |
| 插入 | 可以在顺序表最后添加一个新的数据,在其他位置插入数据的时候需要将相应的数据后移再插入
(插入成本高) |
数据可以随意插入,只需要将前一个节点的指针指向新的节点,再将新的节点的指针指向下一个节点 |
| 元素查询 | 索引与内存偏移正相关,只需要知道索引就可以得到相应的内存地址,只需要执行一次数据访问就可以得到数据 | 需要一个节点一个节点的查找才能得到数据,当节点在末尾的时候需要遍历整个链表才能得到数据。
(查询成本高) |



