

既然在Pathlib库中提到了glob()函数,那么我们就专门用一篇内容讲解文件名匹配。其实我们有专门的一个文件名匹配库就叫:glob。不过,glob库的API非常小,但是仅仅应用于文件名的匹配绰绰有余。只要是在实际的项目中需要过滤,或者匹配一组文件,都可以使用该库进行操作。
通配符
星号(*)
话不多说,下面我们使用通配符来匹配文件名,示例如下:
import glob
for name in sorted(glob.glob('text/*')):
print(name)运行之后,效果如下:
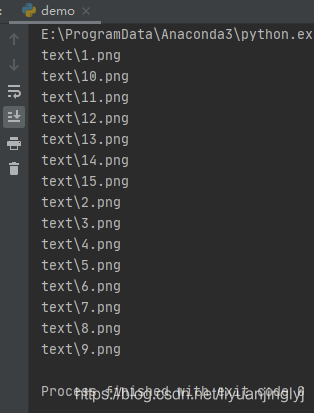
这里不仅用*通配符获取了目录下的所有文件,而且还对其进行了排序。
问号(?)
问号(?)是用来匹配单字的,比如我们赛选上面1开头的图片文件。示例如下:
import glob
for name in glob.glob('text/1?.png'):
print(name)运行之后,效果如下:
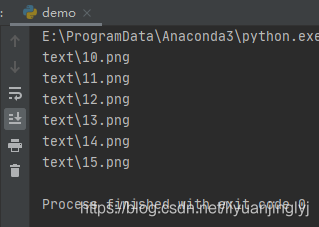
区间匹配([0-9][a-z][A-Z])
从上面两个匹配我们看出来,glob库的匹配规则与正则表达式有些相似。既然它能匹配模糊的,一个或多个字符,那么肯定也可以匹配区间字符。
示例如下:
import glob
for name in glob.glob('text/15[a-z].*'):
print(name)运行之后,效果如下:
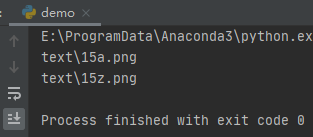
转义元字符
当然,上面的文件名都是常规的文件名,都是用字母与数字组成的。但是,有些人比较怪,可能在文件名中包含了特殊的字符,比如上面的匹配字符“?*[”等。那怎么办呢?用反斜杠“”转义吗?
其实,我们还有更简单的,直接使用escape()函数进行操作。示例如下:
import glob
escape_str='?*[]'
for char in escape_str:
pattern = 'text/*' + glob.escape(char) + '.png'
for name in glob.glob(pattern):
print(name)
运行之后,效果如下:
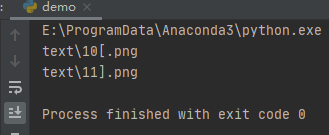
到此python文件名匹配库——clob库就介绍到这了,更多使用Python库请搜索W3Cschool以前的文章或继续浏览下面的相关文章。



